Getting Started in R and Rstudio
Parts 1 & 2
2024-09-19
Introduction to R

What is R?
- A programming language
- Focus on statistical modeling and data analysis
- import data, manipulate data, run statistics, make plots
- Useful for data science
- Great visualizations
- Also useful for most anything else you’d want to tell a computer to do
- Interfaces with other languages i.e. python, C++, bash
![]()
For the history and details: Wikipedia
- an interpreted language (run it through a command line)
- procedural programming with functions
- Why “R”?? Scheme inspired S (invented at Bell Labs in 1976) which inspired R since 1st letters of original authors (free and open source! in 2000)
What is RStudio?
R is a programming language
RStudio is an integrated development environment (IDE) = an interface to use R (with perks!)

Open RStudio on your computer (not R!)
RStudio anatomy

Read more about RStudio’s layout in Section 3.4 of “Getting Used to R, RStudio, and R Markdown” (Ismay and Kennedy 2021)
Creating reproducible reports with Quarto

Quarto = .qmd file = Code + text \(\to\) html
.qmd files contain code + markdown syntax which can be “rendered” to other formats (html, pdf, Word, etc)
.qmd file 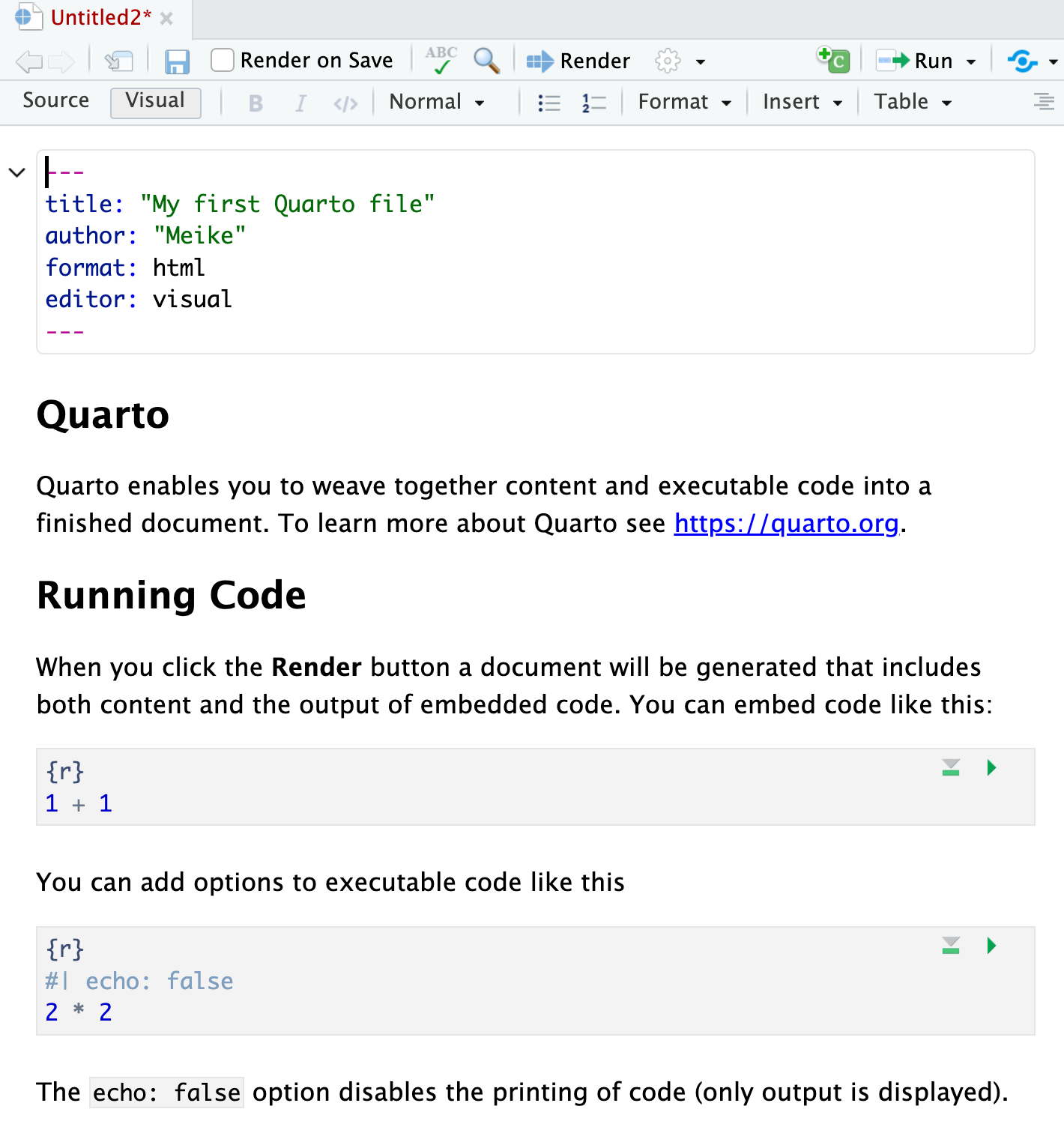
html output
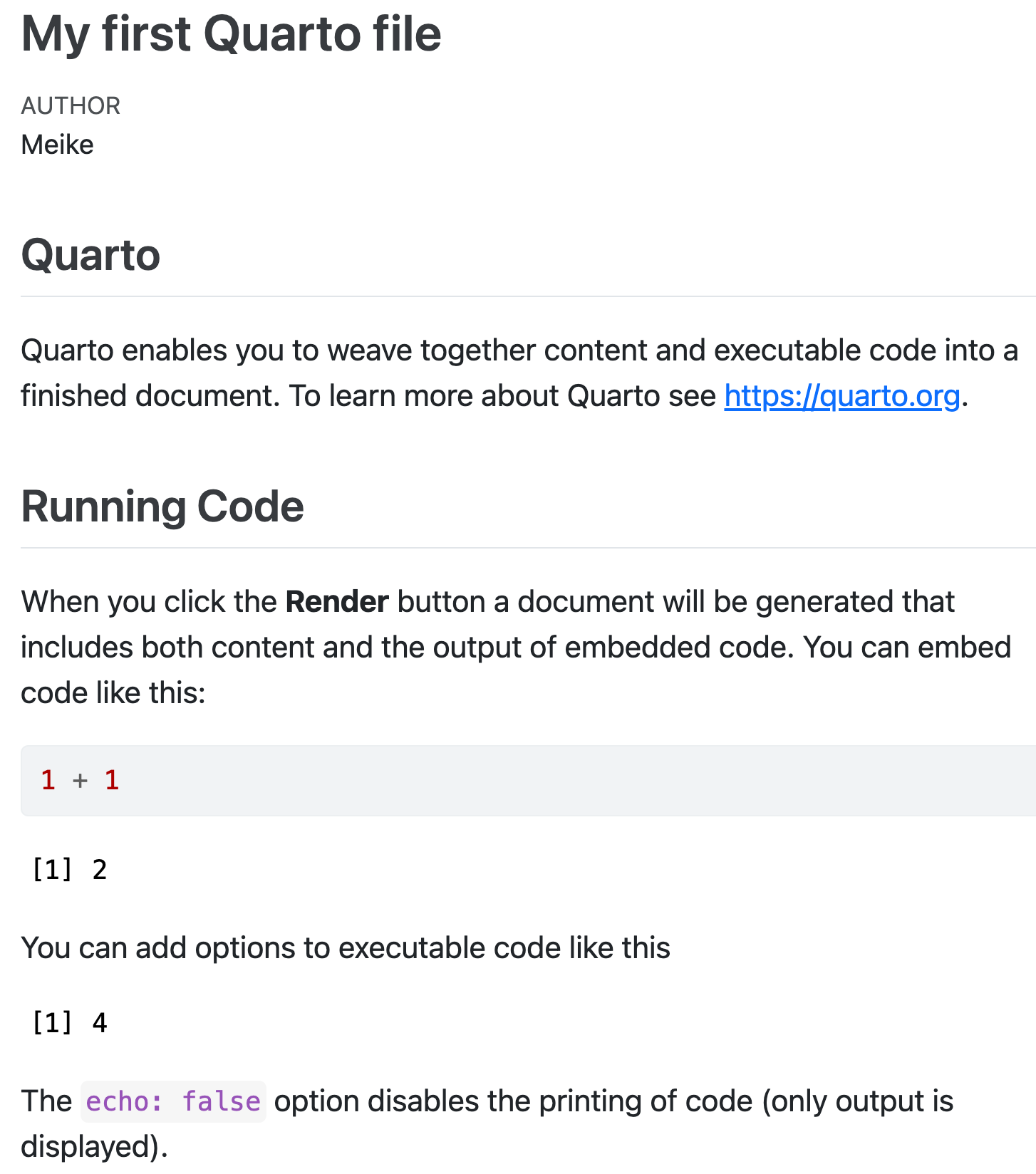
Basic Quarto example

1. Create a Quarto file (.qmd)
Two options:
- click on File \(\rightarrow\) New File \(\rightarrow\) Quarto Document…\(\rightarrow\) OK,
- or in upper left corner of RStudio click on
![]() \(\rightarrow\)
\(\rightarrow\) ![]()


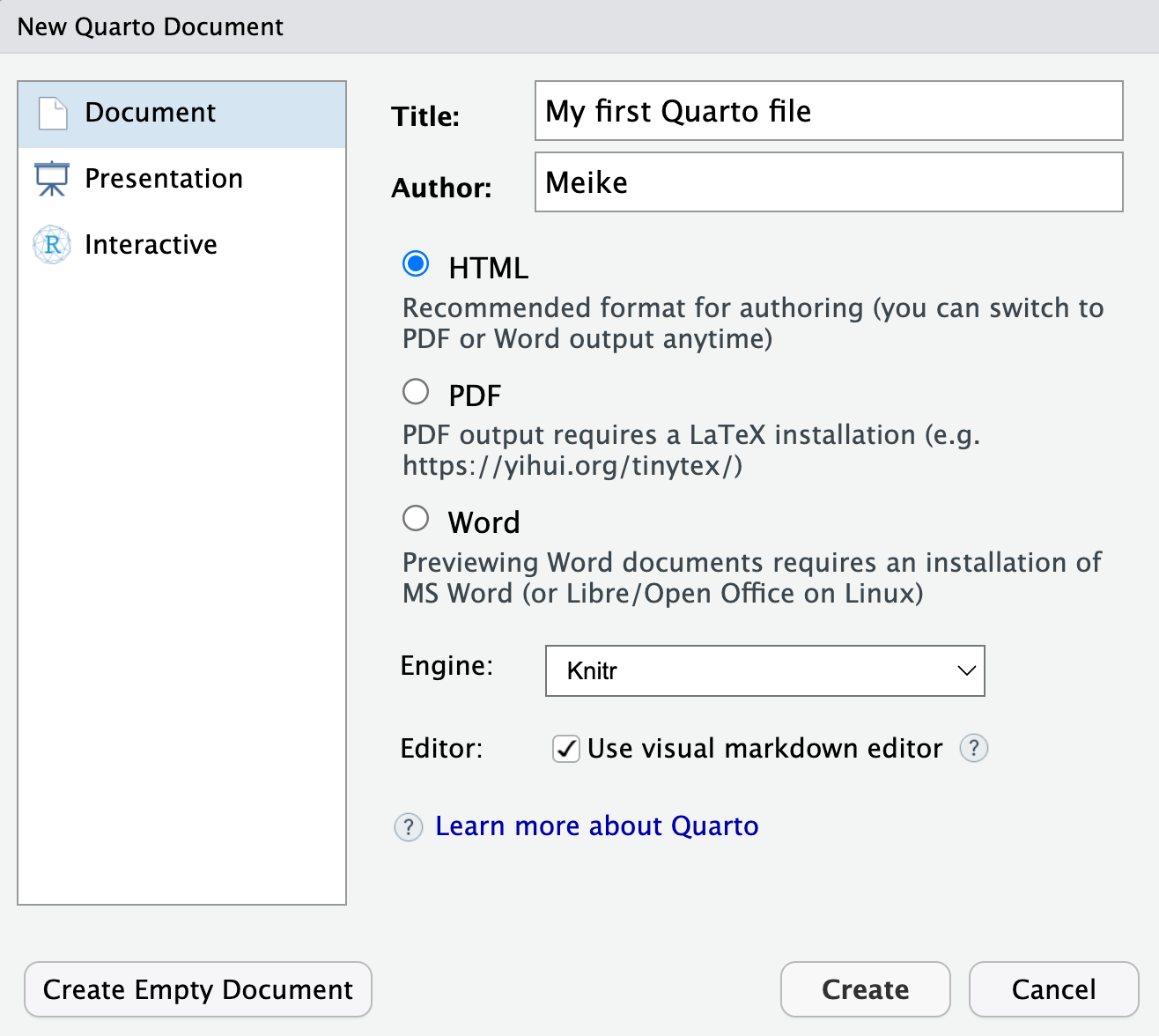
Pop-up window selections:
- Enter a title and your name
- Select
HTMLoutput format (default) - Engine: select
Knitr - Editor: Select
Use visual markdown editor - Click
Create
2. Create a Quarto file (.qmd)
- After clicking on
Create, you should then see the following in your editor window:
3. Save the Quarto file (.qmd)
- Save the file by
- selecting
File -> Save, - or clicking on
![]() (towards the left above the scripting window),
(towards the left above the scripting window), - or keyboard shortcut
- PC: Ctrl + s
- Mac: Command + s
- selecting
- You will need to specify
- a filename to save the file as
- ALWAYS use .qmd as the filename extension for Quarto files
- the folder to save the file in
- a filename to save the file as
4. Create (render) html file
We create the html file by rendering the .qmd file.
Two options:
- click on the Render icon
![]() at the top of the editor window,
at the top of the editor window, - or use keyboard shortcuts
- Mac: Command+Shift+K
- PC: Ctrl+Shift+K
- A new window will open with the html output.
- You will now see both .qmd and .html files in the folder where you saved the .qmd file.
Note
- The template .qmd file that RStudio creates will render to an html file by default.
- The output format can be changed to create a Word doc, pdf, slides, etc.
.qmd file vs. its html output
.qmd file
html output
3 types of Quarto content
- Code chunks
- Text, lists, images, tables, links (covered in Quarto workshop)
- YAML metadata (covered in Quarto workshop)

Code chunks
.qmd file
html output
What does a code chunk look like?
An empty code chunk looks like this:
Visual editor
![]()
Source editor
![]()
Important
Note that a code chunks start with ```{r} and ends with ```. Make sure there is no space before ```.
Enter and run code (1/2)
- Type R code inside code chunks
- Select code you want to run, by
- placing the cursor in the line of code you want to run,
- or highlighting the code you want to run
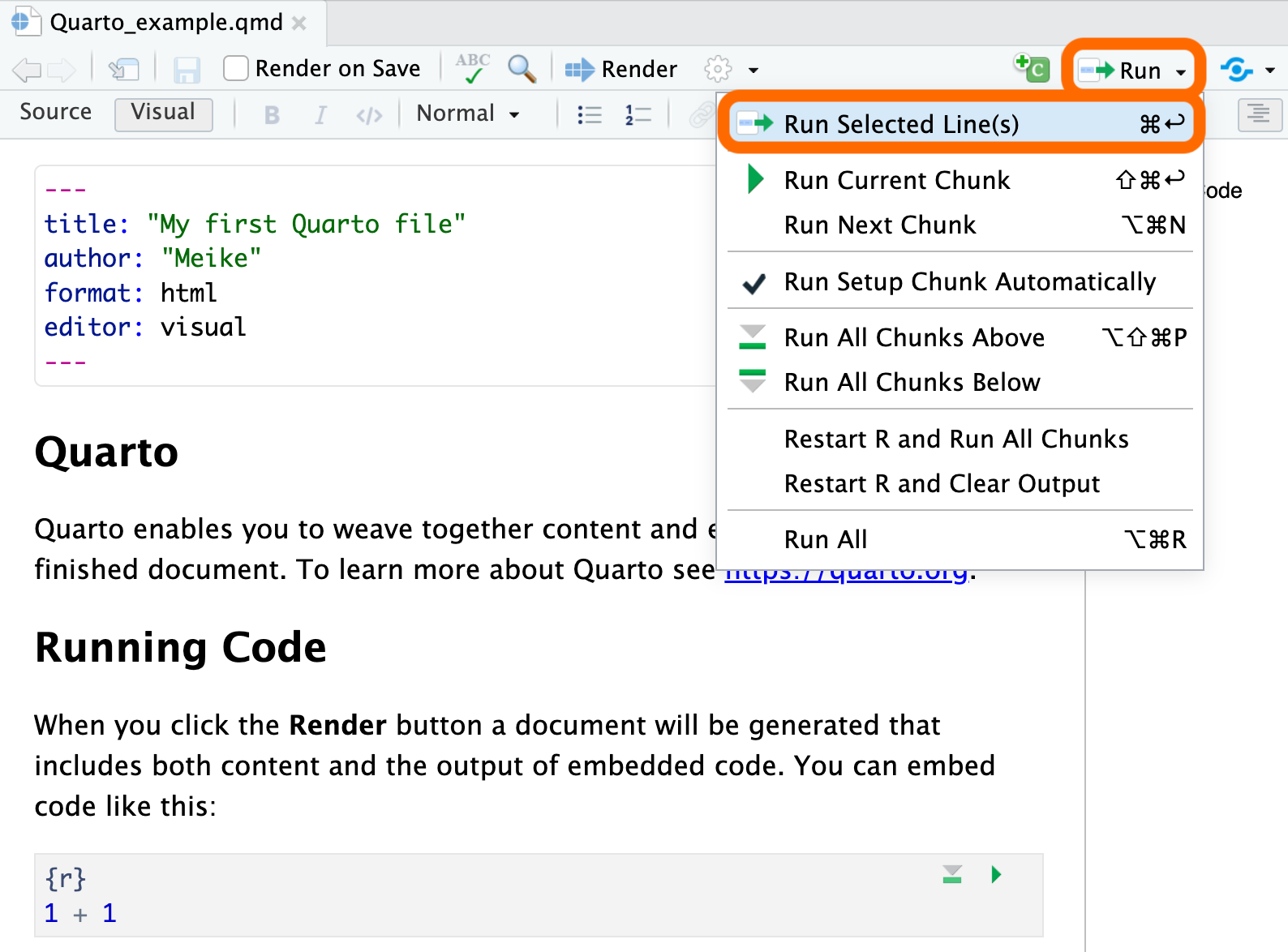
- Run selected code by
- clicking on the
![]() button in the top right corner of the scripting window and choosing
button in the top right corner of the scripting window and choosing Run Selected Line(s), - or typing one of the following key combinations:
- clicking on the
 button in the top right corner of the scripting window and choosing
button in the top right corner of the scripting window and choosing | Mac | ctrl + return |
| PC | command + return |
- Where does the output appear?
Enter and run code (2/2)
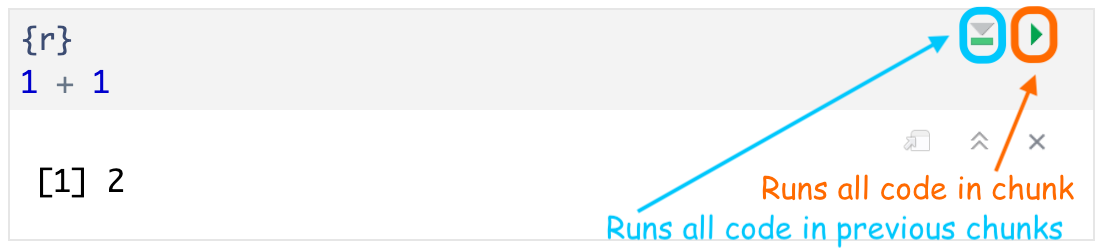
- Run all code in a chunk by
- by clicking the play button in the top right corner of the chunk
- The code output appears below the code chunk
Note
- The output should also appear in the Console.
- Settings can be changed so that the output appears only in the Console and not below the code chunk:
- Select {{< fa solid gear >}} (to right of Render button) and then Chunk Output in Console.
Create a code chunk
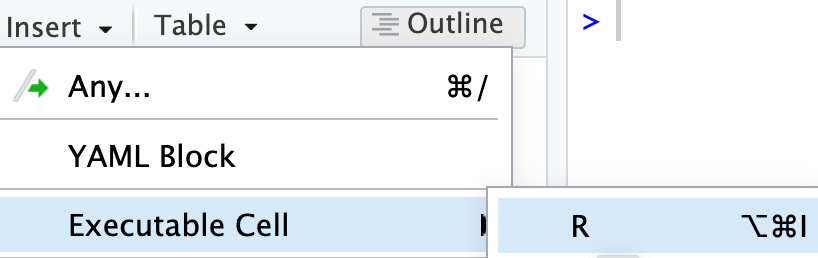
3 options to create a code chunk
Click on
![]() at top right of the editor window, or
at top right of the editor window, orKeyboard shortcut
| Mac | Command + Option + I |
| PC | Ctrl + Alt + I |
Visual editor: SelectInsert->Executable Cell->R
R Packages: install & load

What are R Packages?
A good analogy for R packages is that they
are like apps you can download onto a mobile phone:
Installing packages
- Packages contain additional functions and data
Two options to install packages:
install.packages()or- The “Packages” tab in Files/Plots/Packages/Help/Viewer window
- Only install packages once (unless you want to update them)
- Installed from Comprehensive R Archive Network (CRAN) = package mothership
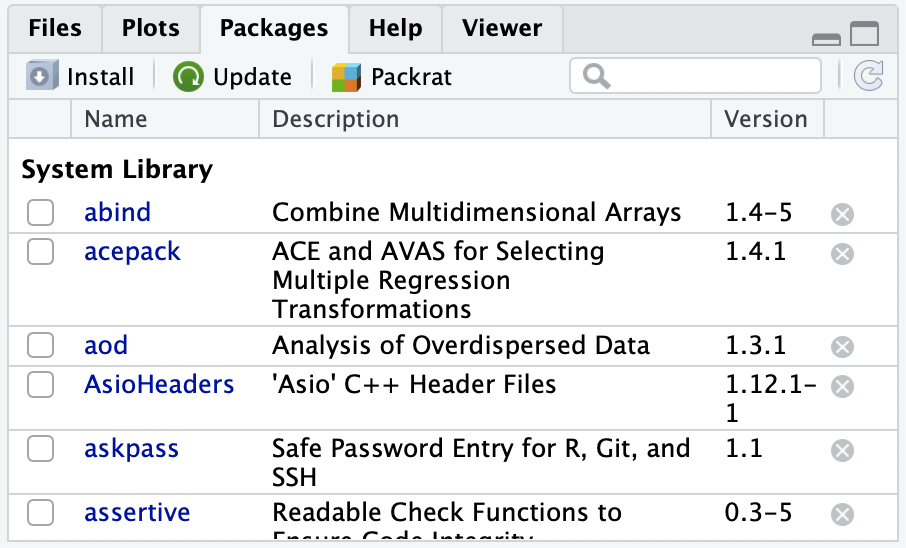
Load packages with library() command
- Use the
library()command to load each required package. - Packages need to be loaded every time you open Rstudio.
- The code to load packages MUST be in your qmd file.
- Tip: at the top of your qmd file, create a chunk that loads all of the R packages you want to use in that file.
- Check to see whether a package has been loaded:
- Go to Packages tab
- If box to left of package name is checked off, then it’s loaded
Data basics in R

Load data from an .xlsx (Excel) file: point & click option
SAVE THE CODE after using the point & click option
- In RStudio’s Files window, open the
datafolder and- then click on the dataset
toy_data.xlsx.
- then click on the dataset
- Select the
Import Dataset...option,- Import Options: Type in
NAin the “NA:” box, and - then click on the
Importbutton on the bottom right of the pop-up window.
- Import Options: Type in
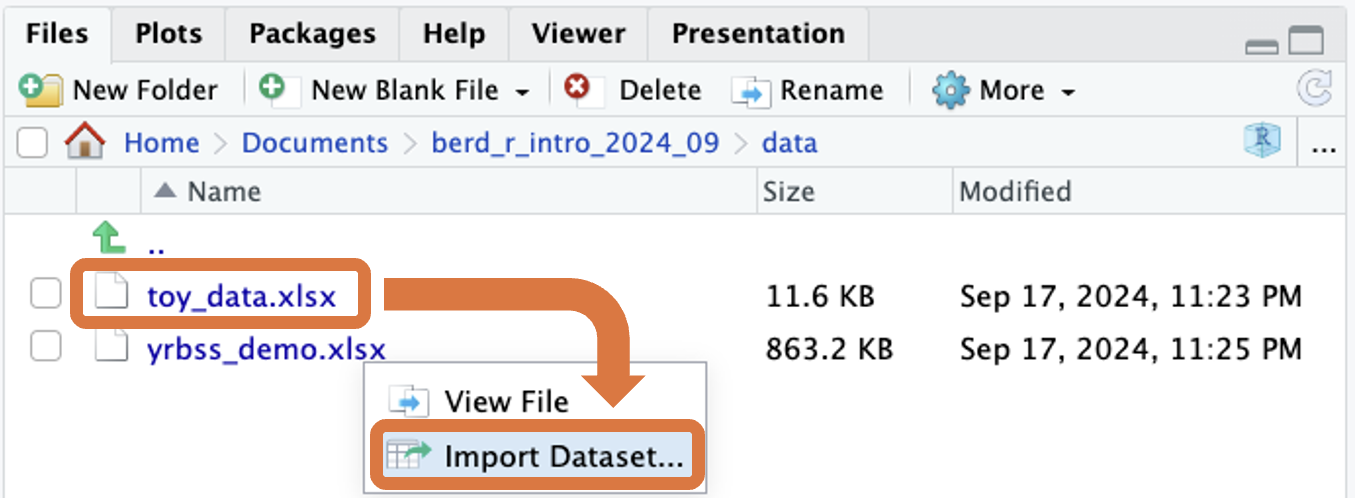
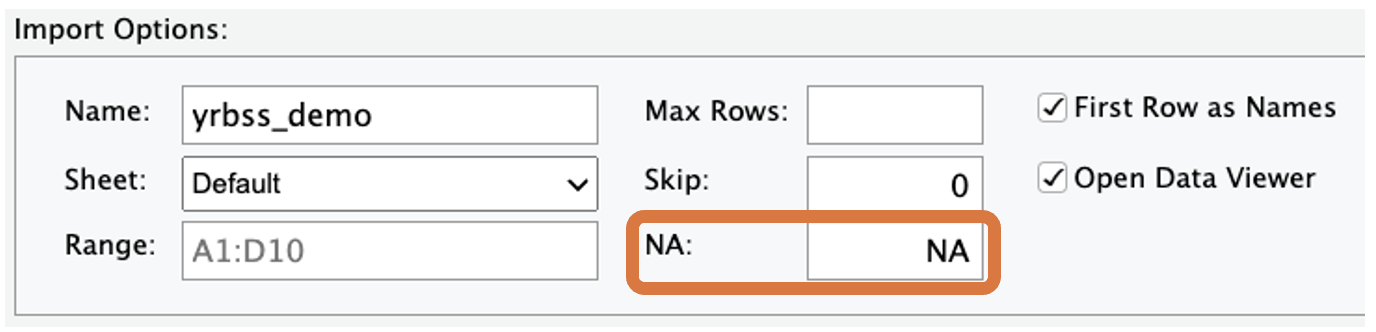
- Copy the code from the console used to load the file into your script (omitting the + sign):
View the toy_data dataset
- A new tab in the scripting window will appear with the
toy_datadataset. - Note that the code chunk in the qmd file specifies
#| eval: FALSEso that this code is not run while rendering the qmd file.
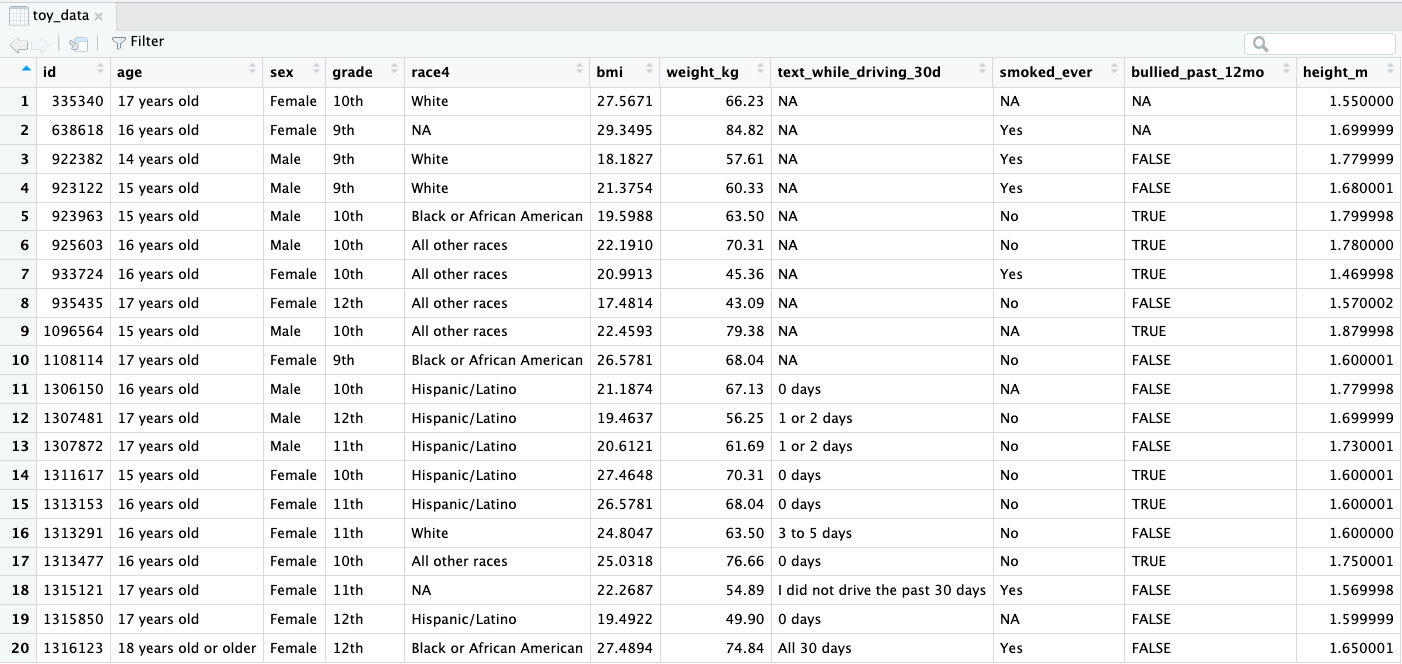
View the YRBSS dataset
- Run the
Viewcommand below within RStudio.- A new tab in the scripting window will appear with the
yrbss_datadataset.
- A new tab in the scripting window will appear with the
- Note that the code chunk specifies
#| eval: FALSEso that this code is not run while rendering the .qmd file.
First 20 rows shown below:
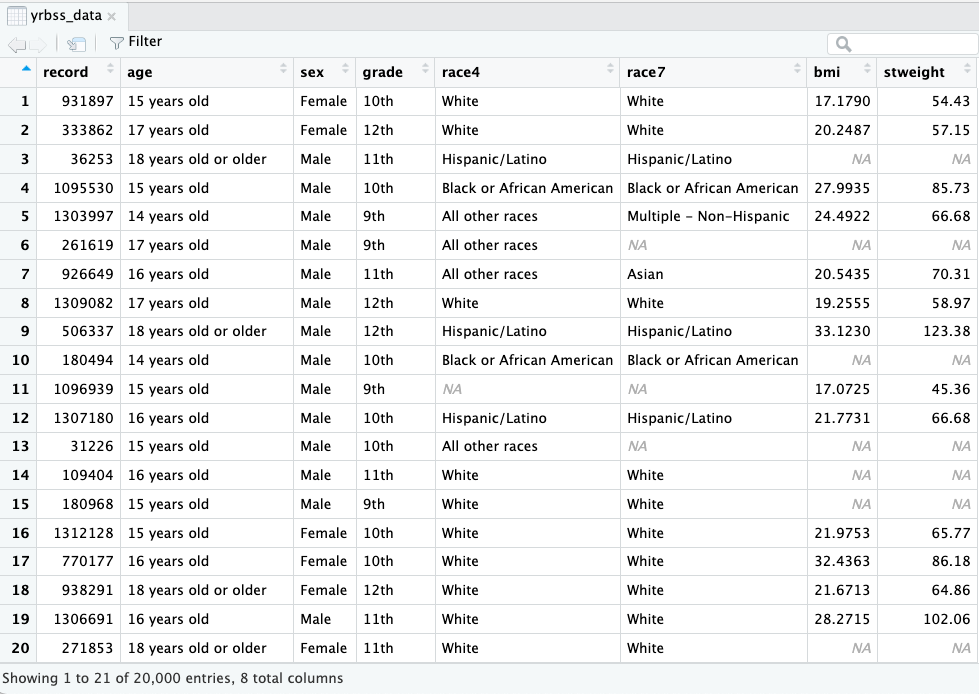
Data visualization
- This is a very brief introduction to creating plots using the
ggplot2package.- The
ggplot2package gets loaded with thetidyverseand thus we do not need to load it separately.
- The


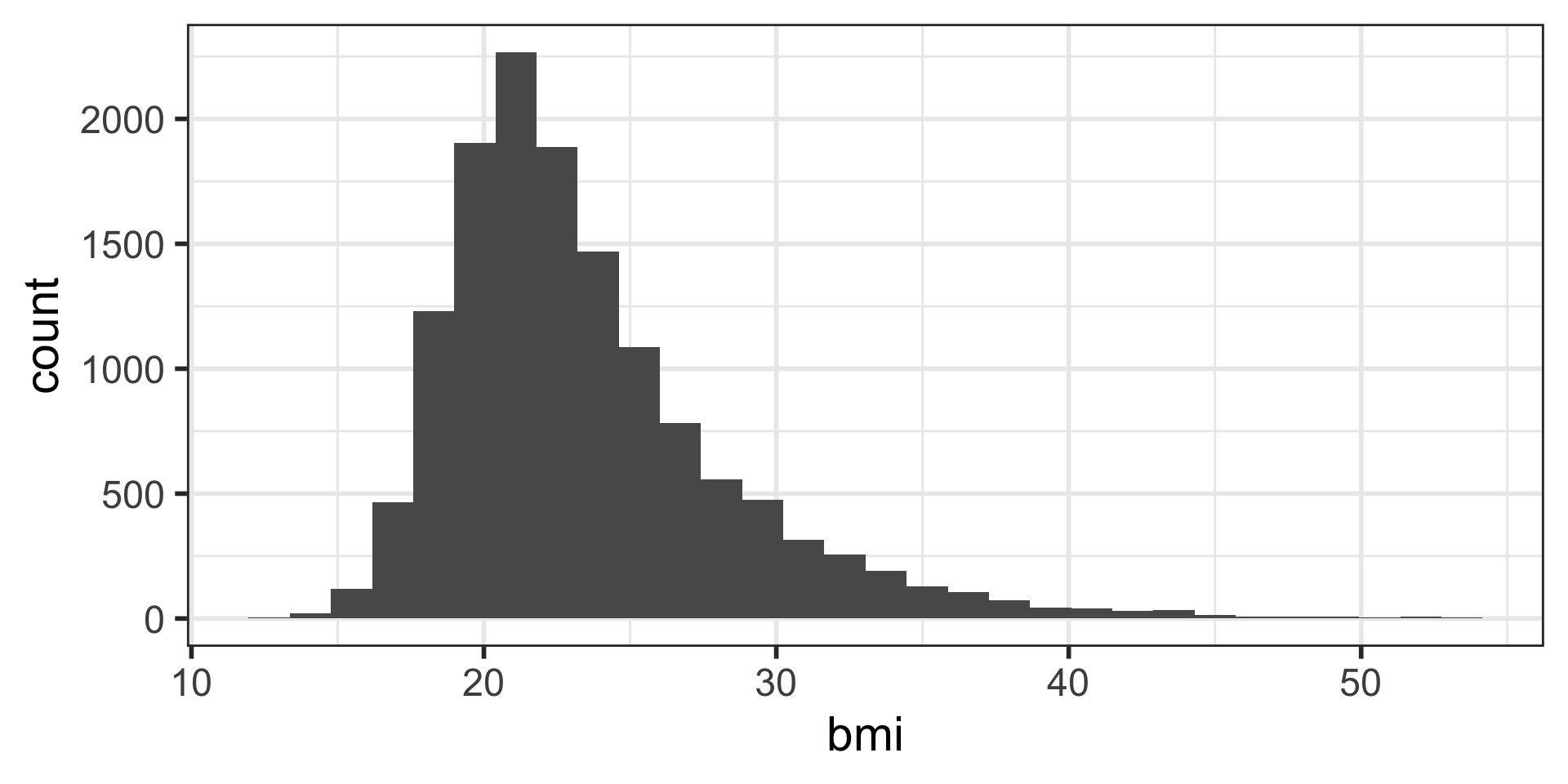
Histograms
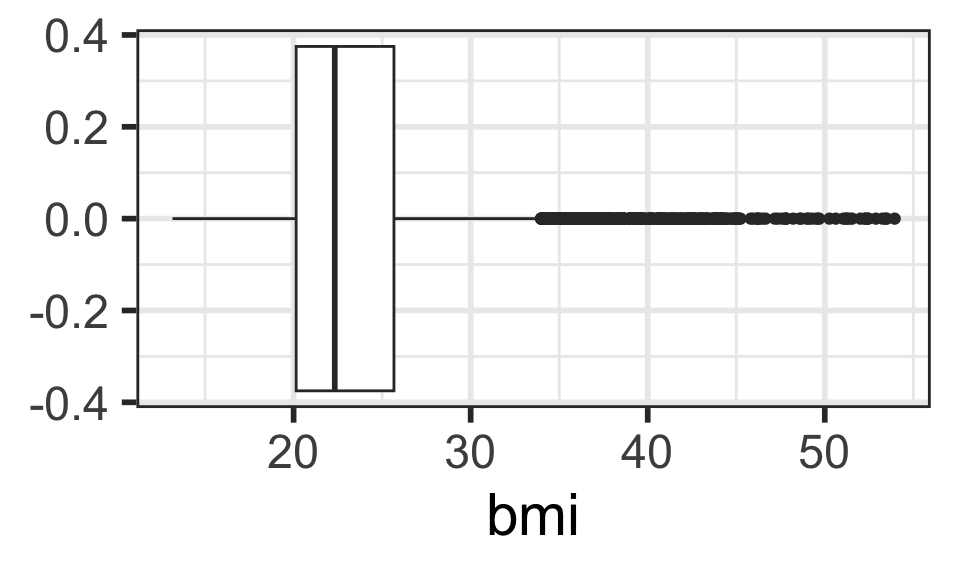
Boxplots
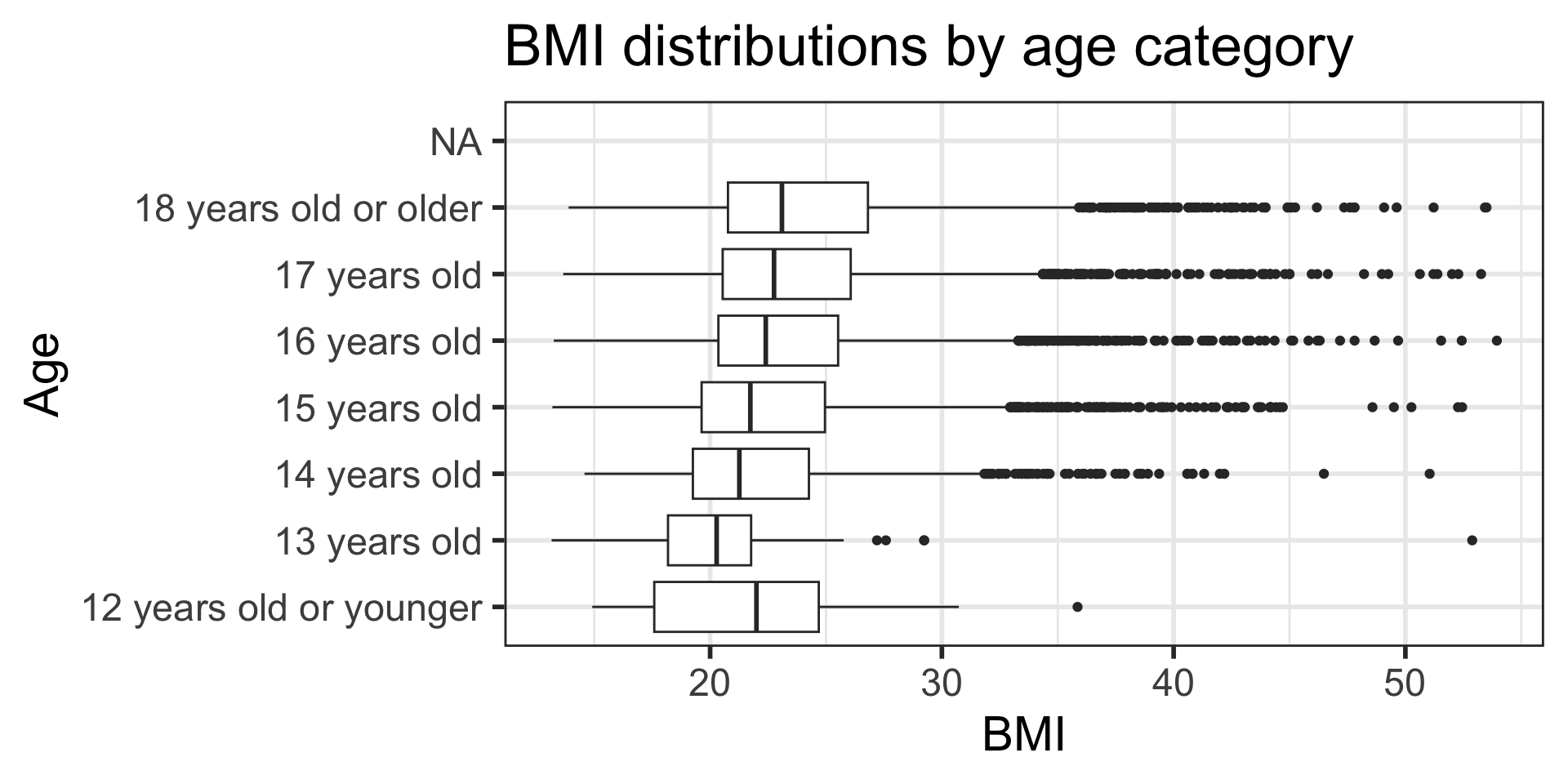
- Recall that the whiskers’ ends are the minimum and maximum values
- The box is from the first to third quartiles, with the line inside the box at the median
BMI:
horizontal boxplot (specify x = ...)
Stratified boxplots (plus axis labels & title!)
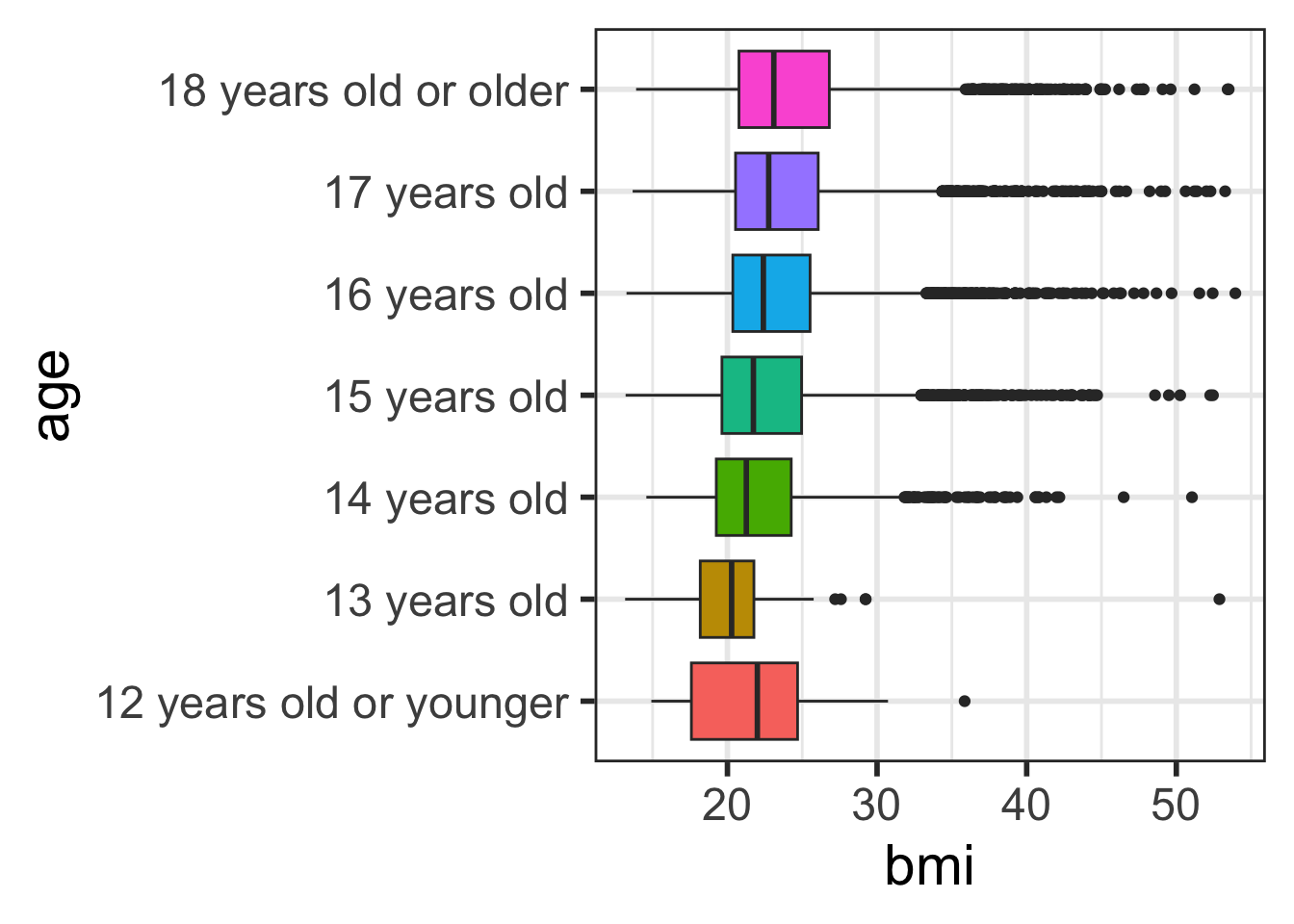
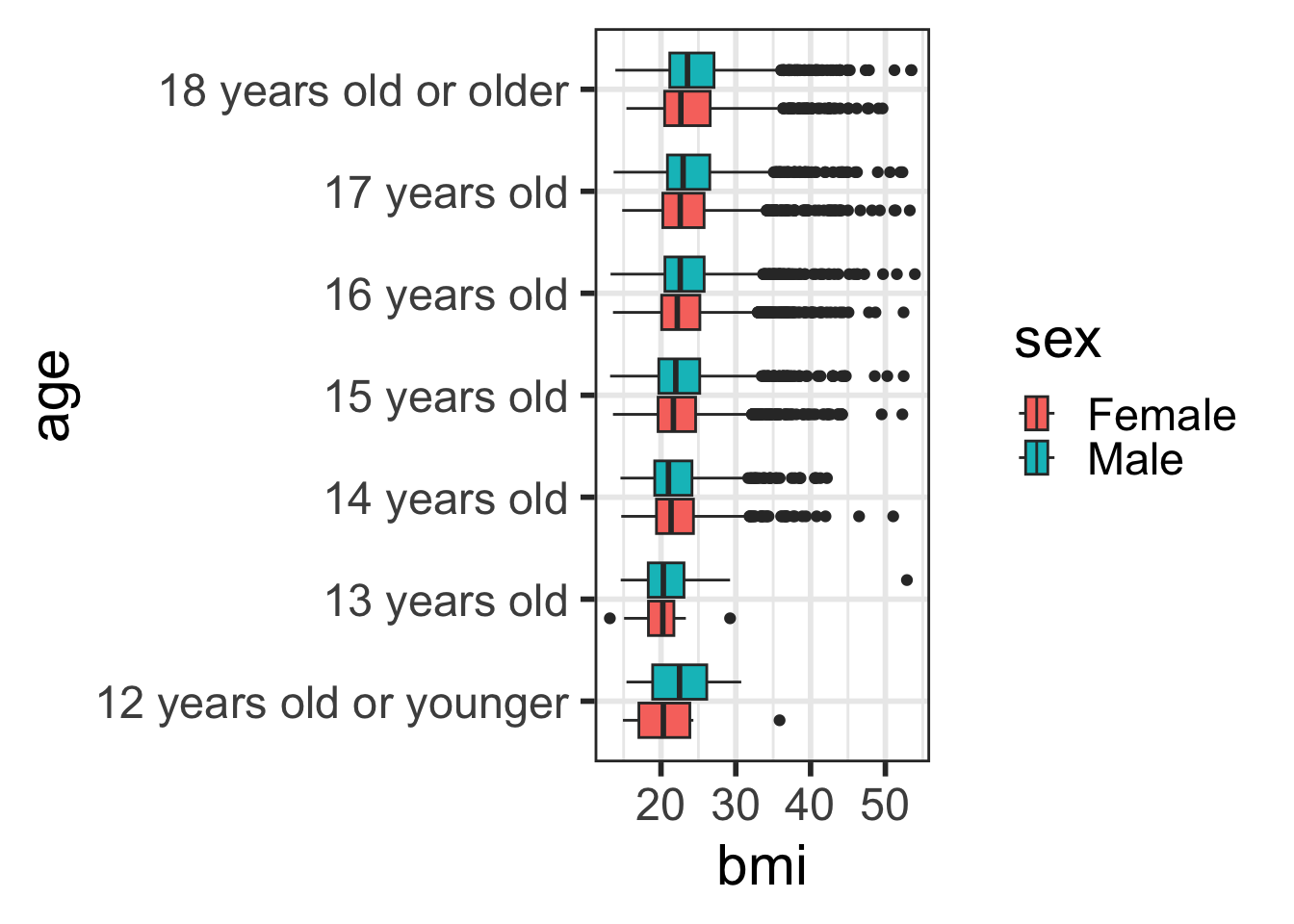
Add color using fill
- Also remove the
NAcategory withdrop_na()(we will talk about this in later slides) - What’s the difference in use of
fill=here?
Scatterplots
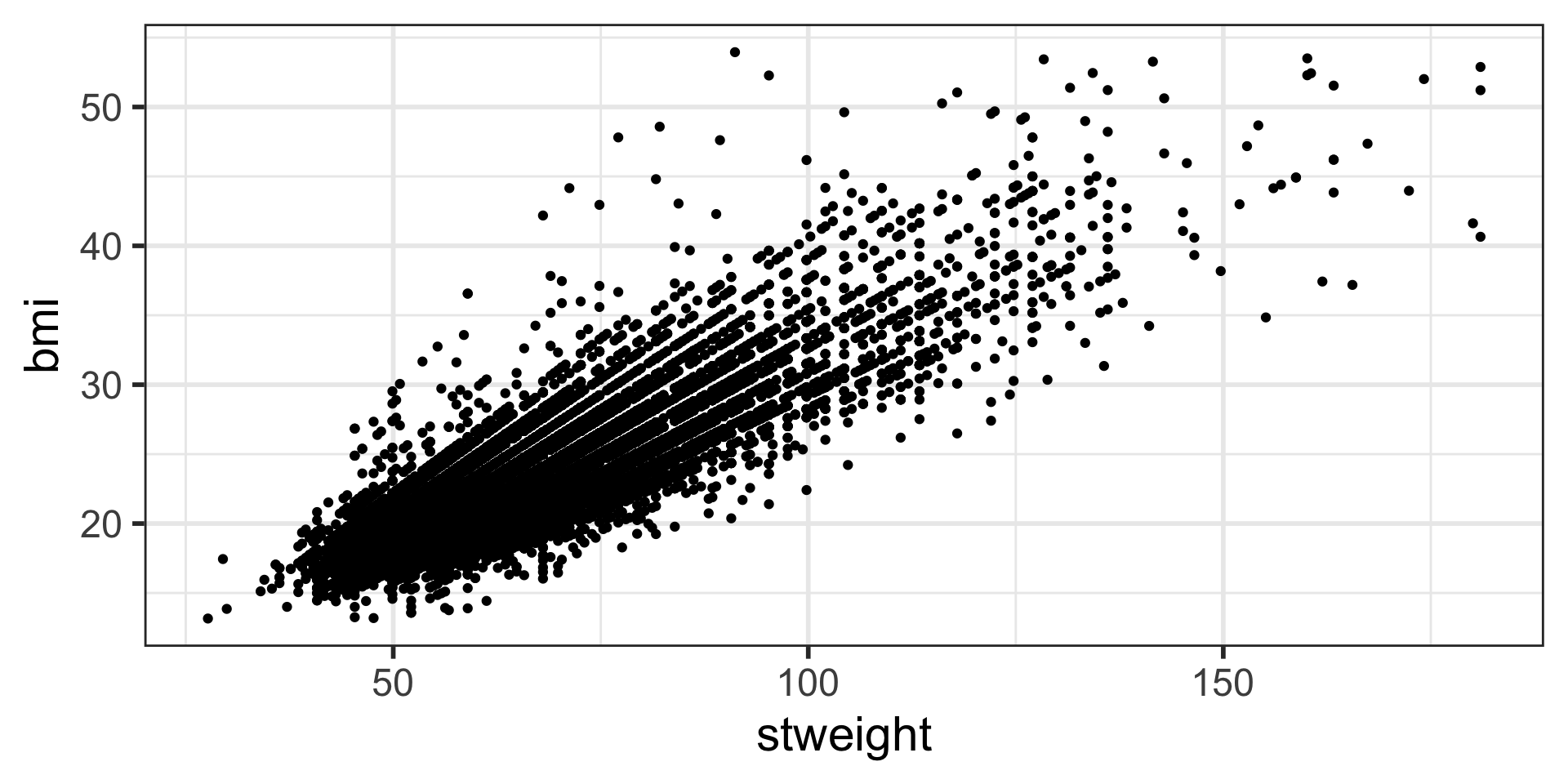
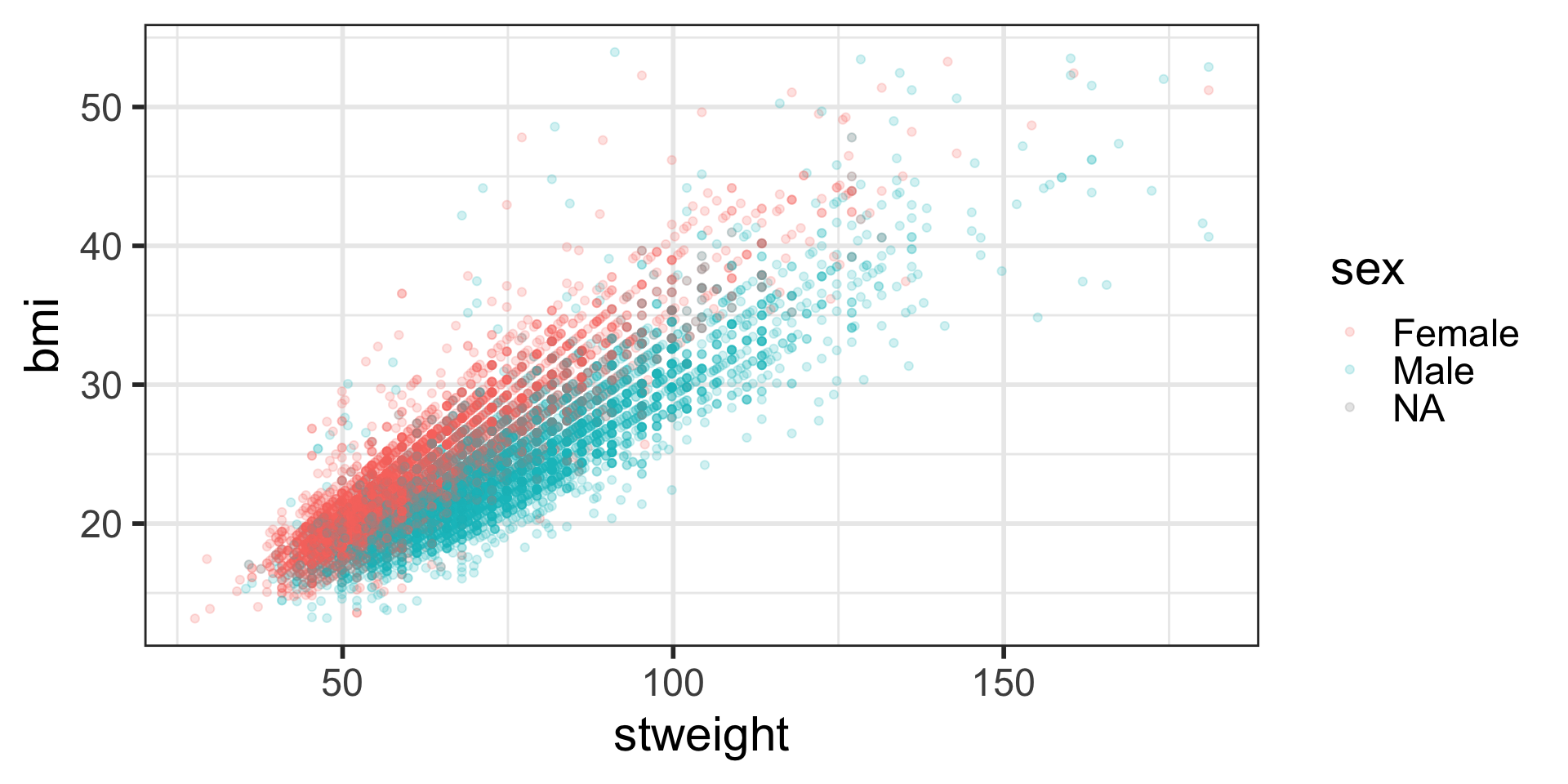
Scatterplot with color-coded dots
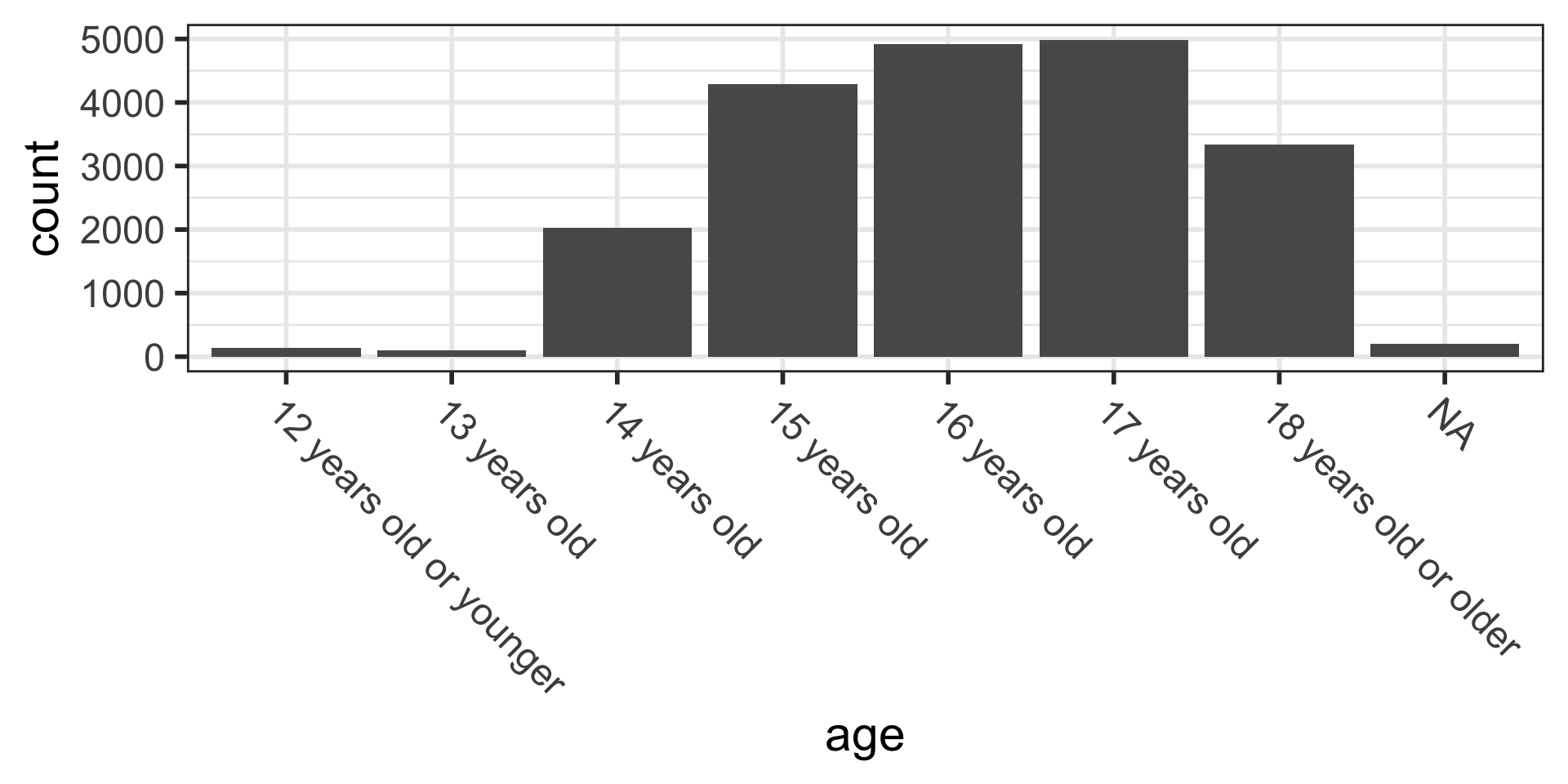
Barplots
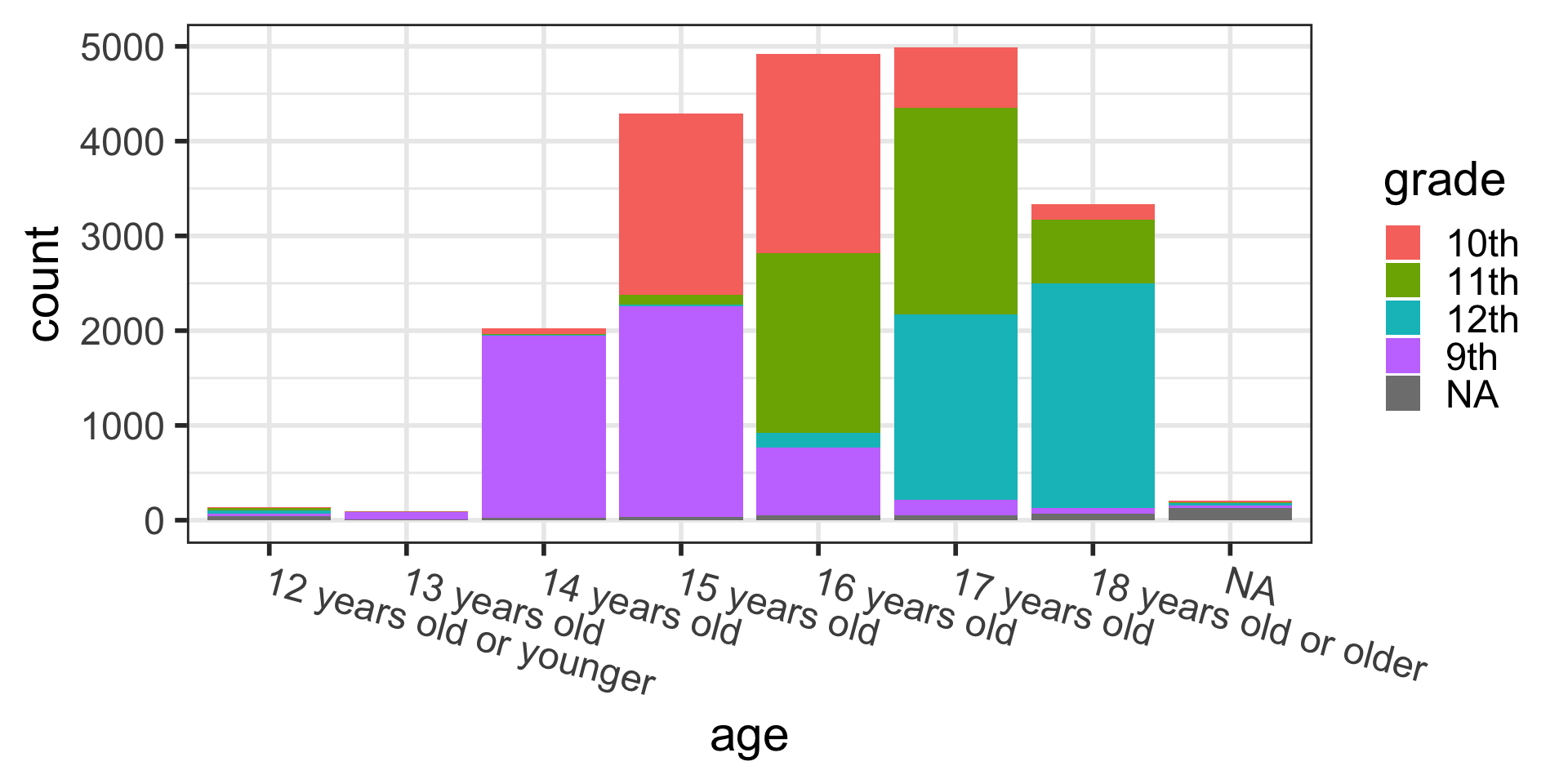
By default, barplots display counts (frequencies) on the vertical axis:
Barplots with proportions
* To show proportions, the code is more complicated.
ggplot(data = yrbss_data,
aes(x = age)) +
# specify aesthetics within the barplot to show proportions
geom_bar(aes(y = after_stat(prop), group = 1)) +
# Next line converts y-axis labels to percentages instead of proportions
scale_y_continuous(labels = scales::percent_format()) +
# "dodge" the x-axis labels
scale_x_discrete(guide = guide_axis(n.dodge = 2))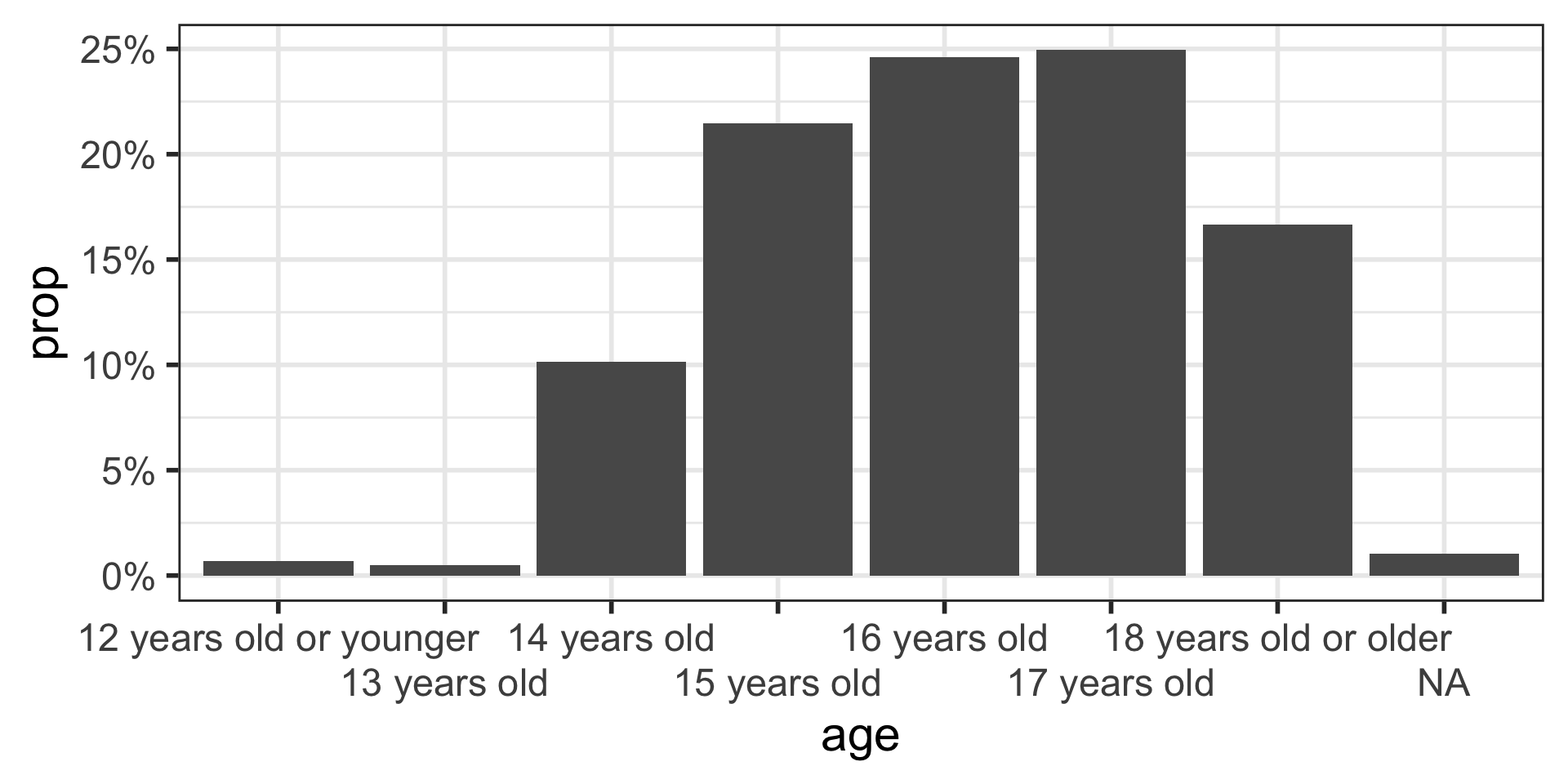
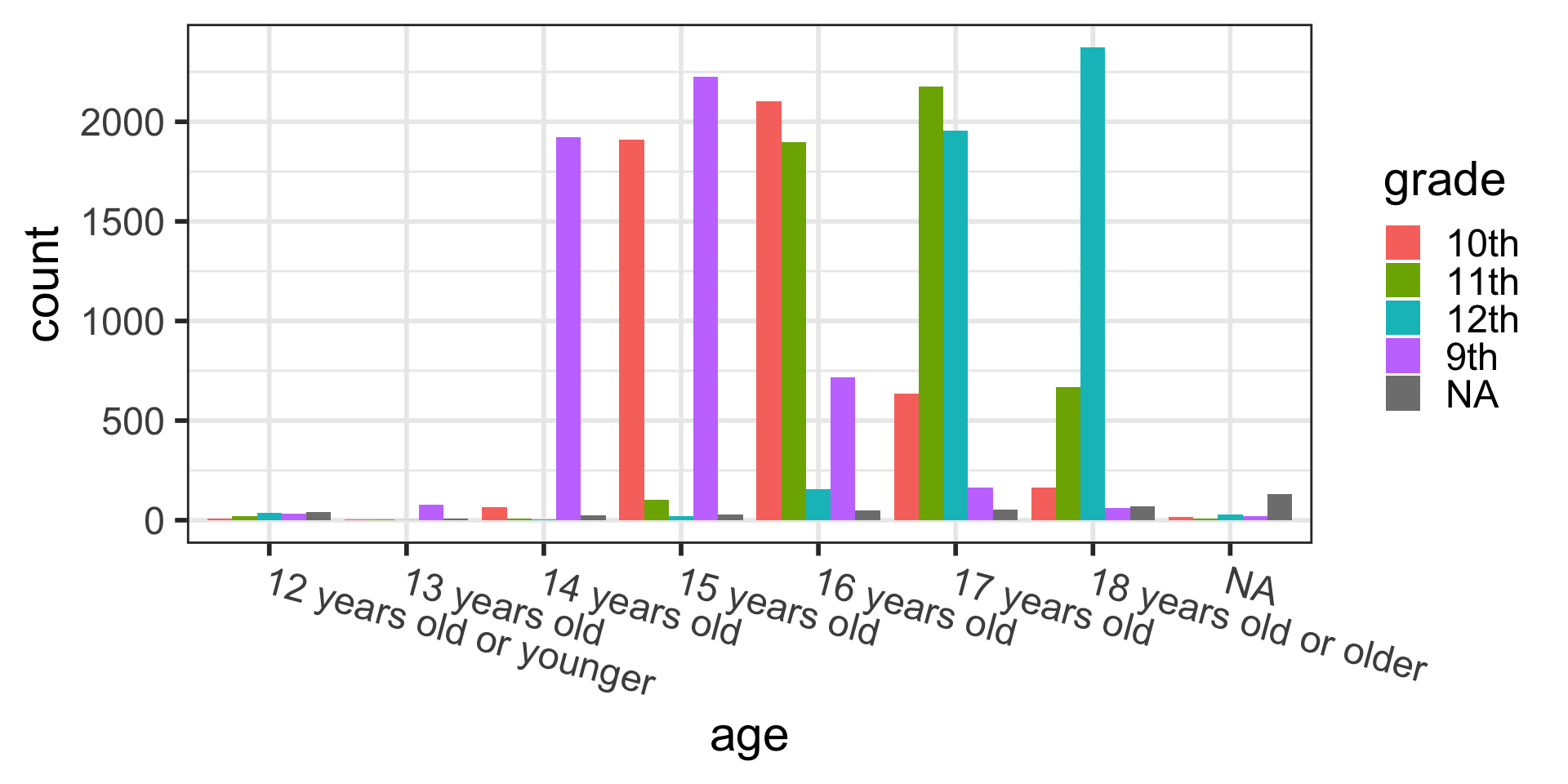
Barplots with 2 variables: segmented bar plots
Stacked bars showing counts:
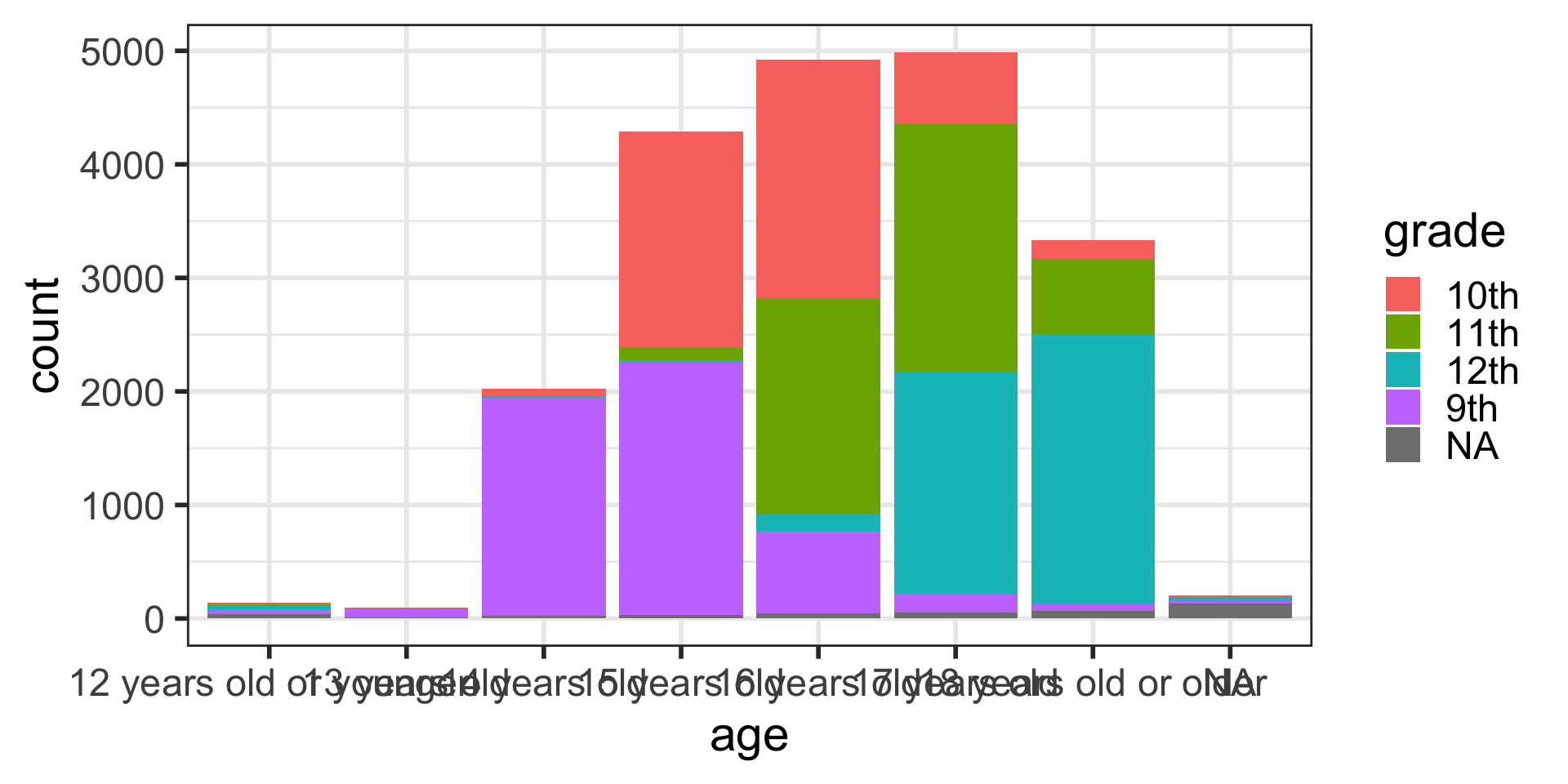
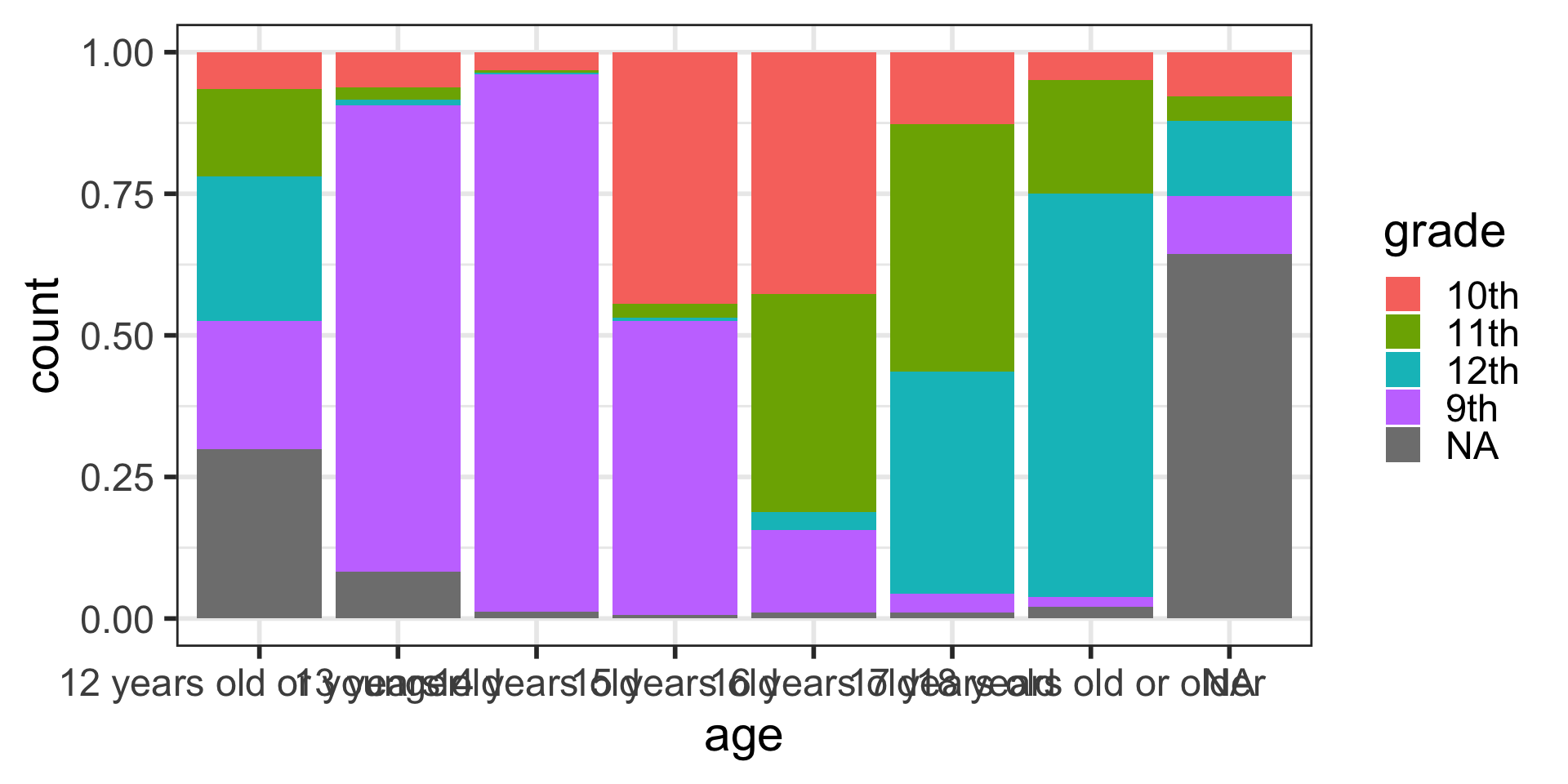
Side-by-side barplots
Saving a ggplot as an image file
First, create a plot and save it as an R object:
Save the plot as a pdf (or “jpeg”, “tiff”, “png”, etc.)
Can specify the dpi when saving, many journals have dpi requirements.
See ggsave webpage for more details:
Missing data summary & visualization
- I highly recommend the tutorial: Exploring missing values in
naniarhttps://allisonhorst.shinyapps.io/missingexplorer/ - These slides have some highlights of tools presented in the tutorial
Load the naniar package if haven’t already:

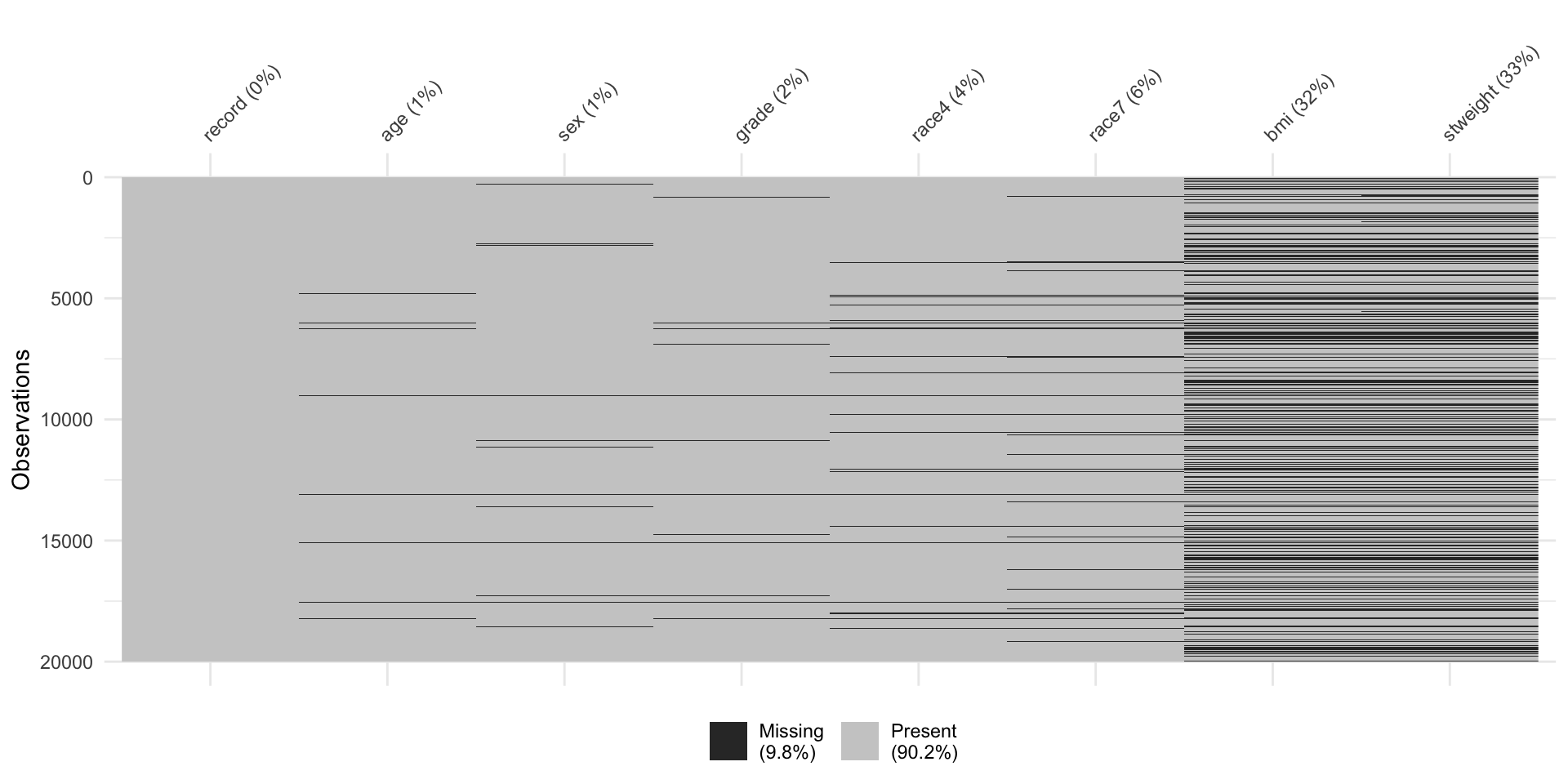
Visualizing missing data across dataset
- This plot helps visualize whether
- there are variables with a lot of missing values and/or
- participants with a lot of missing values
- Each row is an observation
- Columns are for the different variables in the dataset
- Black = missing, grey = not missing
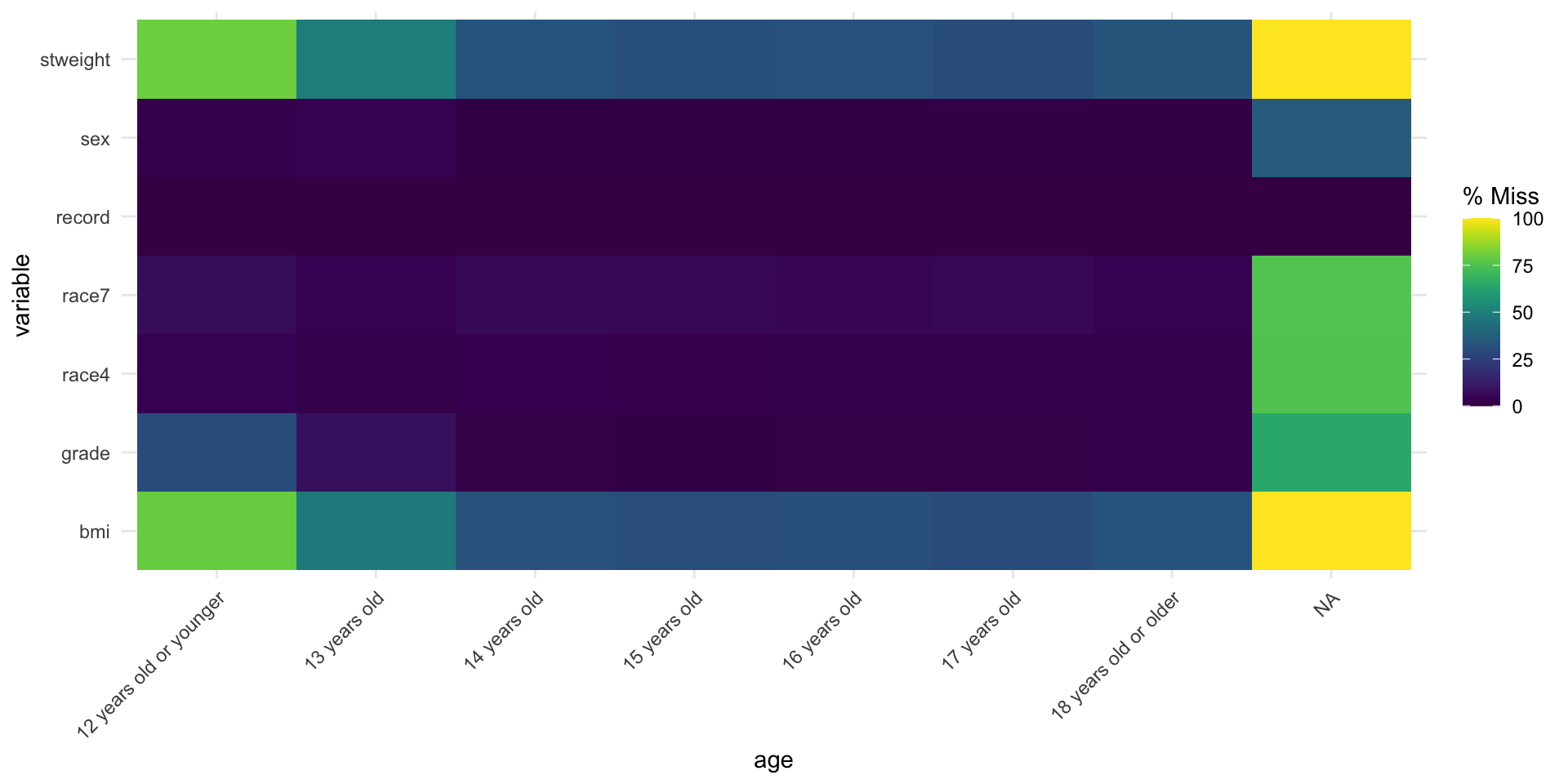
Missingness heatmap by group
- This plot is useful in comparing missingness rates stratified by a variable
- Specify the variable to stratify the missingness heatmap by in the
fct =option
Example: Percent missingness stratified by age group
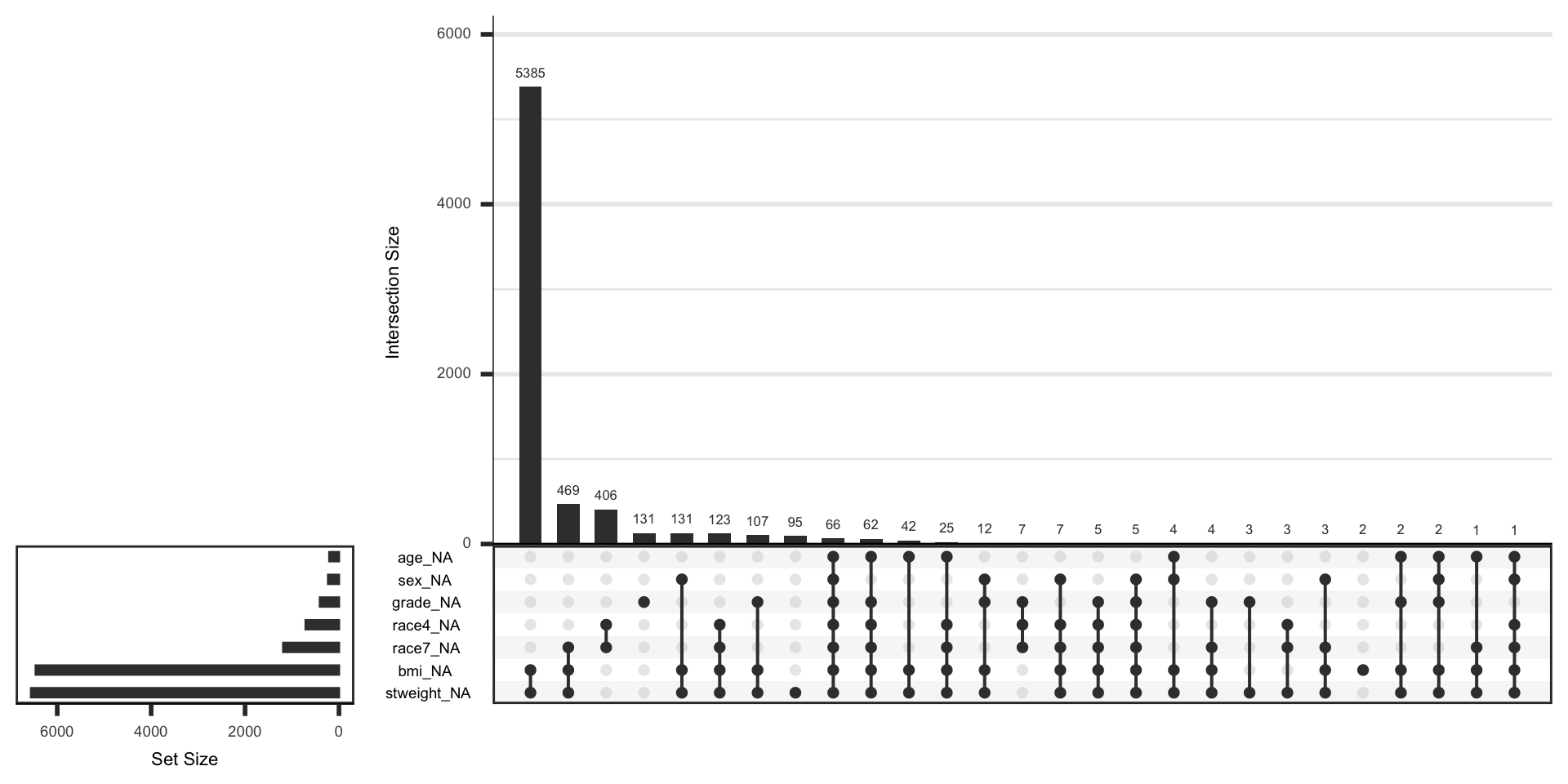
Missingness intersections (UpSet plot)
- UpSet plots are great for finding sets of variables that have a lot of missingess.
Data wrangling
Subsetting data
Subset rows: filter()ing data
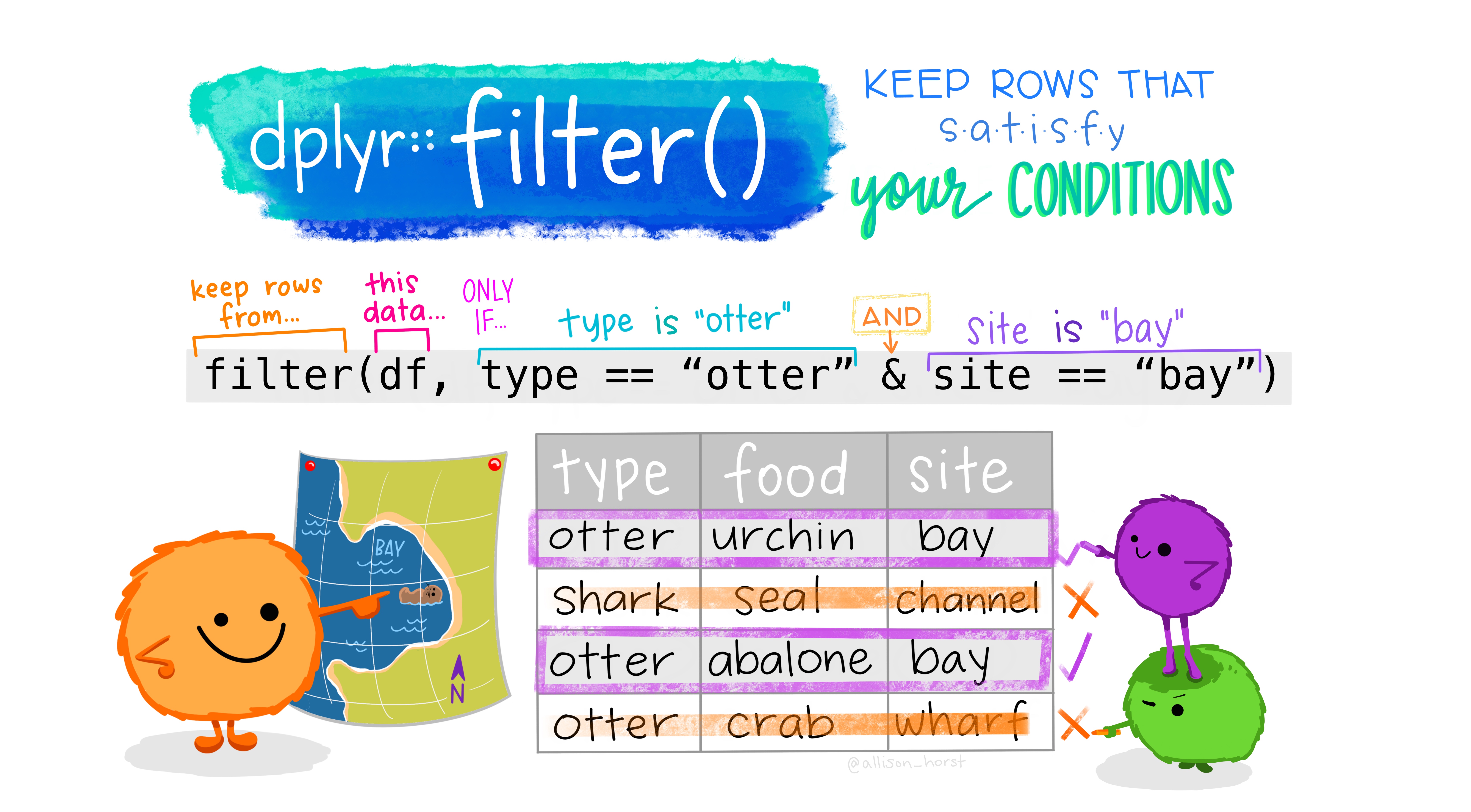
Subset columns: select()ing data
Make new variables: mutate()


mutate() - A confusing name, a powerful dplyr verb
- So what is mutate?
mutate()is one of the most usefuldplyrverbs. - You can use
mutate()to- transform existing data (variables in your
data.frame) and/or - add new variables into the data.frame.
- transform existing data (variables in your
Think of this like adding a formula in Excel to calculate the value of a new column based on previous columns. You can do lots of things such as:
- subtract one column from another
- convert the units of one column to new units (such as days to years)
- change the capitalization of categories in a variable
- recode a continuous variable to be a categorical one
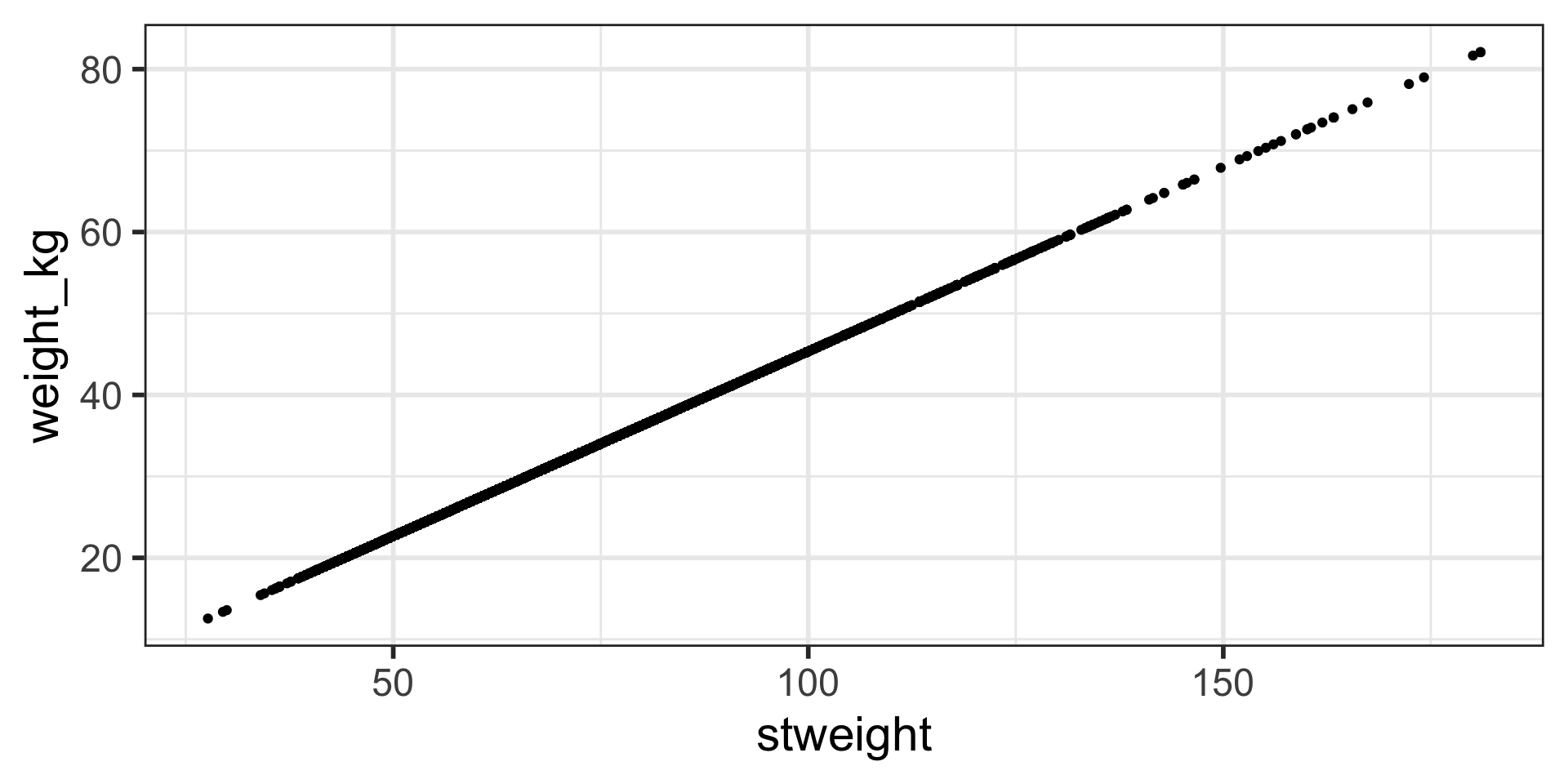
Using mutate to calculate a new variable based on other variables (3/3)
Figure examining the newly created variables using mutate:
Make categorical variables with case_when()
Recall boxplots geom_boxplot()
- Boxplots can be used to compare the distribution of a quantitative variable among categories.
- We need a categorical variable (here, our
xaxis) - and a continuous numeric variable, shown here on our
yaxis.
- We need a categorical variable (here, our
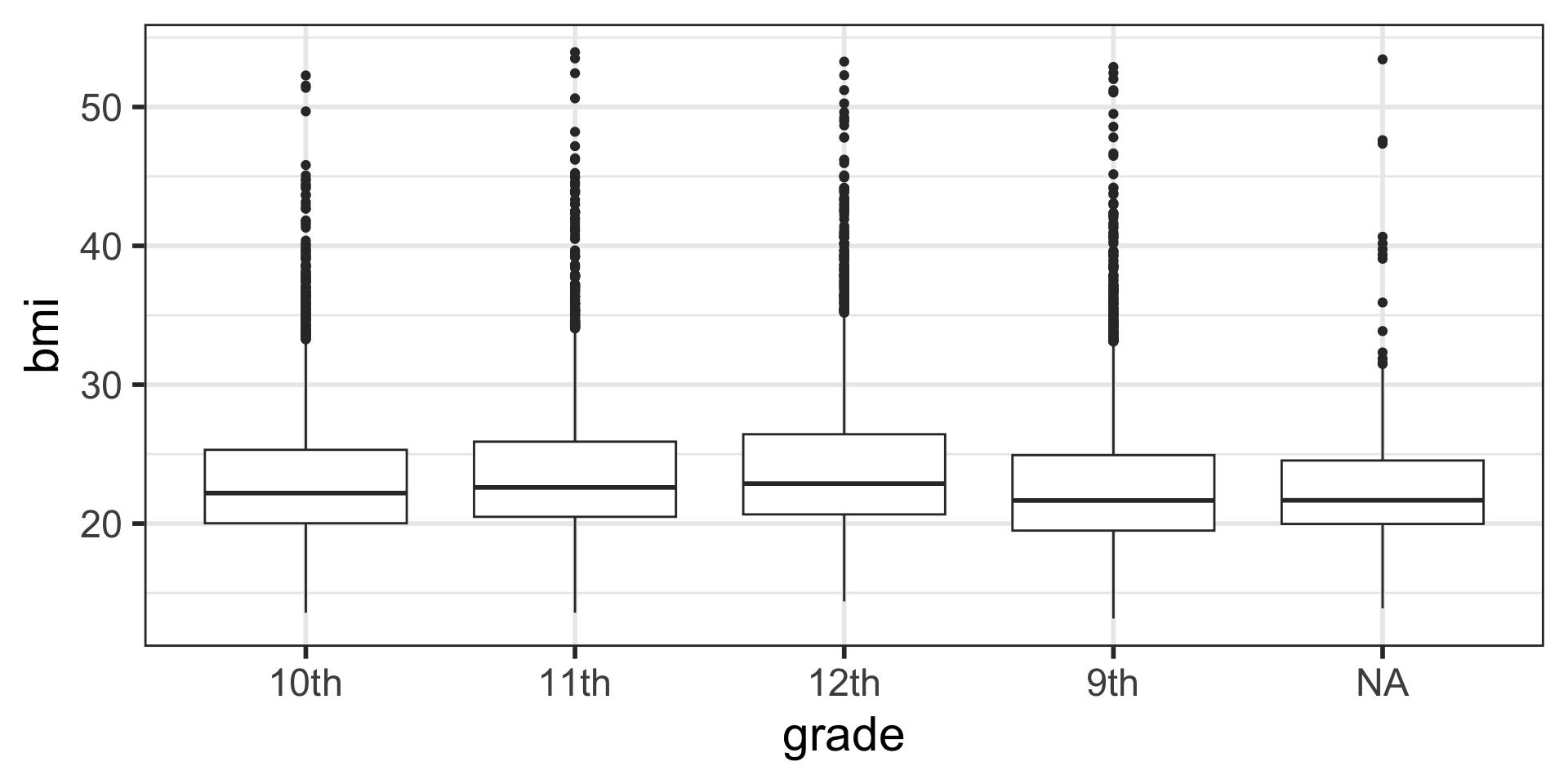
The main differences from the scatterplots we created earlier are the
geomtype and the variables plotted.We can change the color similarly to scatterplots.
- However, we map to
filland notcolorif we want to fill in the box with color:
- However, we map to
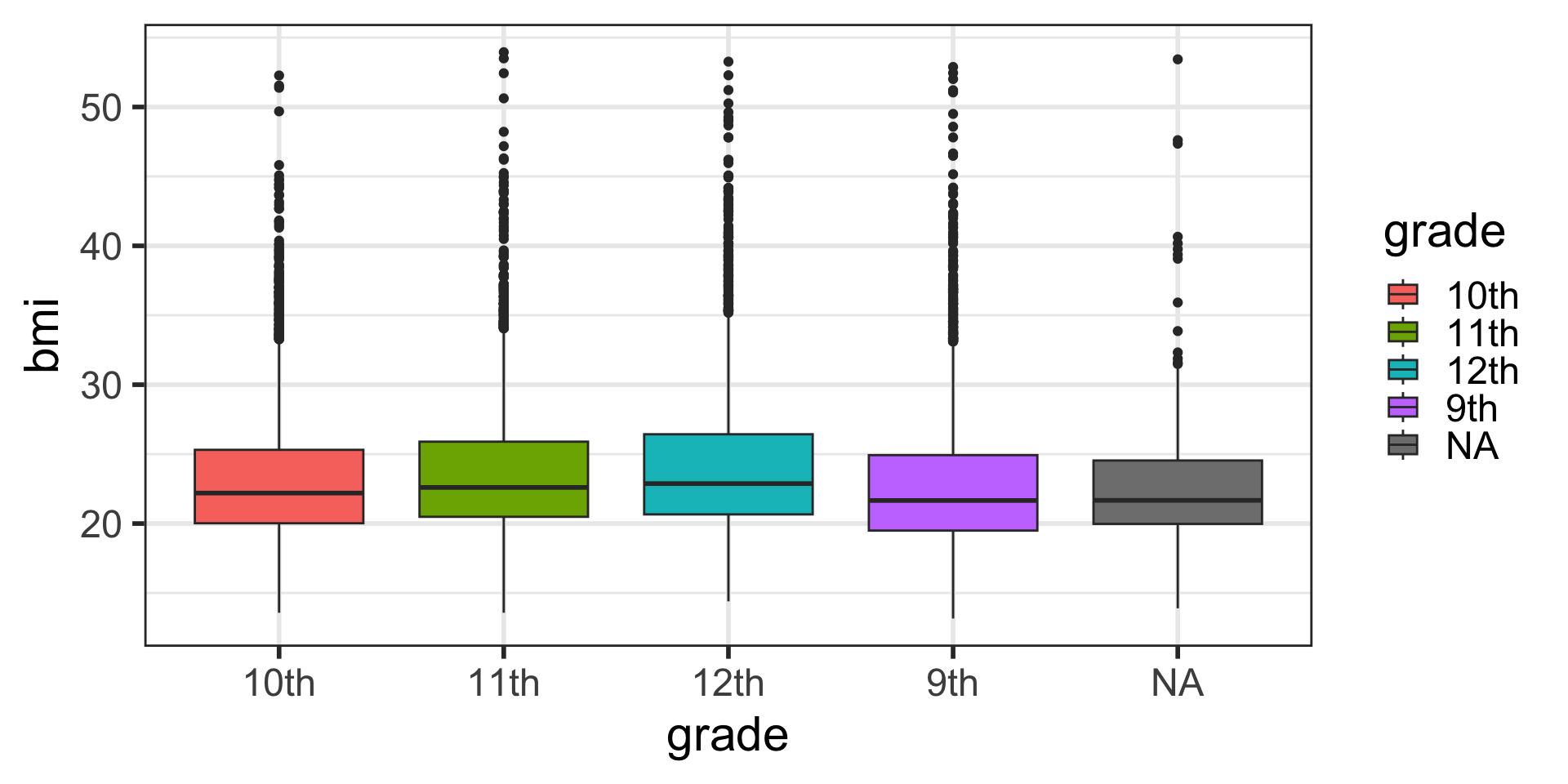
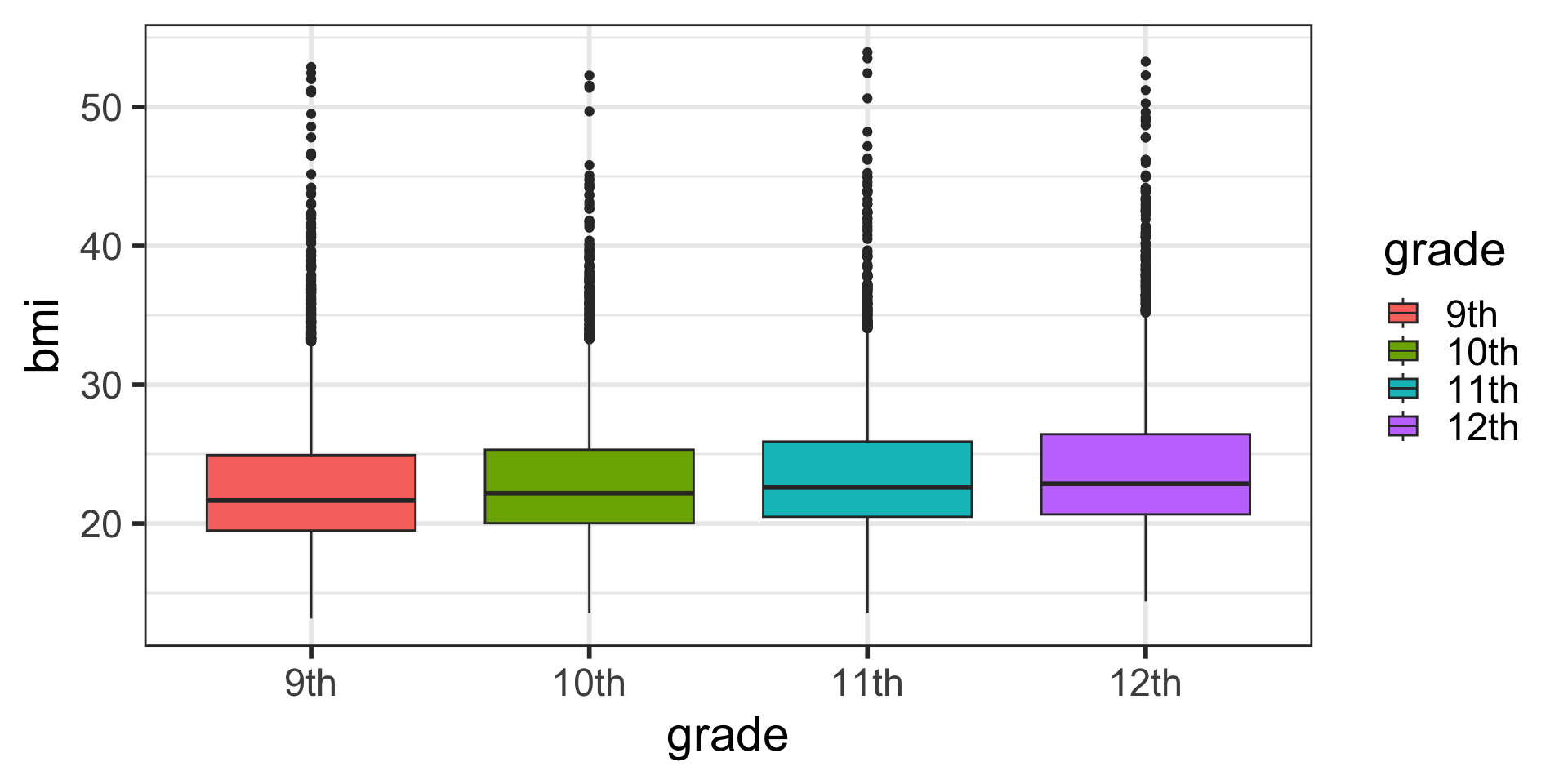
Factor levels when plotting
- Perhaps we want to change the order of the
gradelevels in our plot. - This is where factor levels are useful:
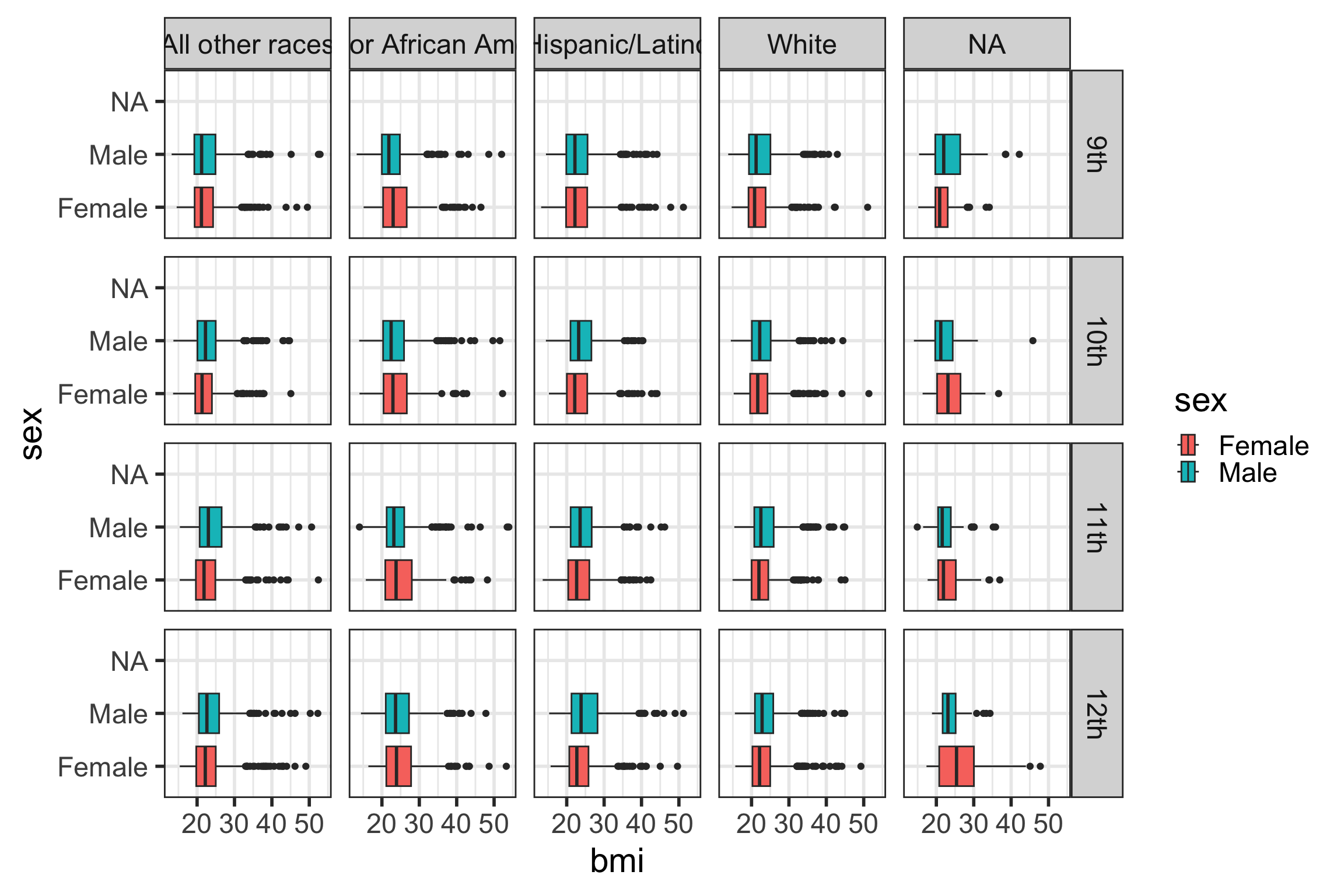
Faceting our boxplot with facet_wrap()
- One of the most powerful ways to change a visualization is by faceting.
- We can make multiple plots stratifying by a categorical variable.
- To do this, we have to add the
facet_wrap()command to our plot.- We need to specify the variable to
facet_wrap-race4by using thevars()function to specify it as a variable.
- We need to specify the variable to
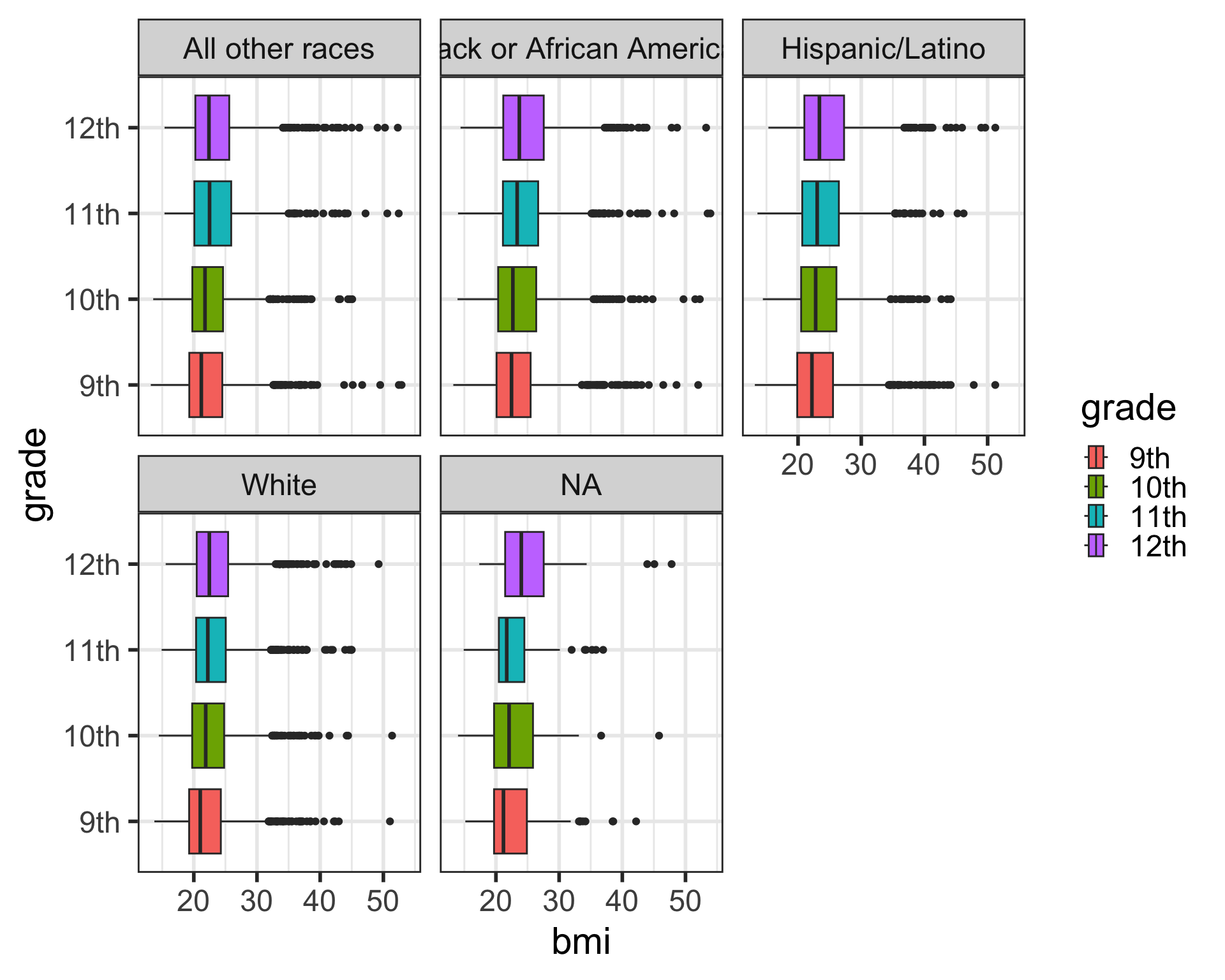
Don’t try to facet on a continous
numericvariable - it won’t work.Don’t forget to look at the help documentation (e.g.,
?facet_wrap) to learn more about additional ways to customize your plots!
Faceting our boxplot with facet_grid()
Conclusions

Artwork by @allison_horst
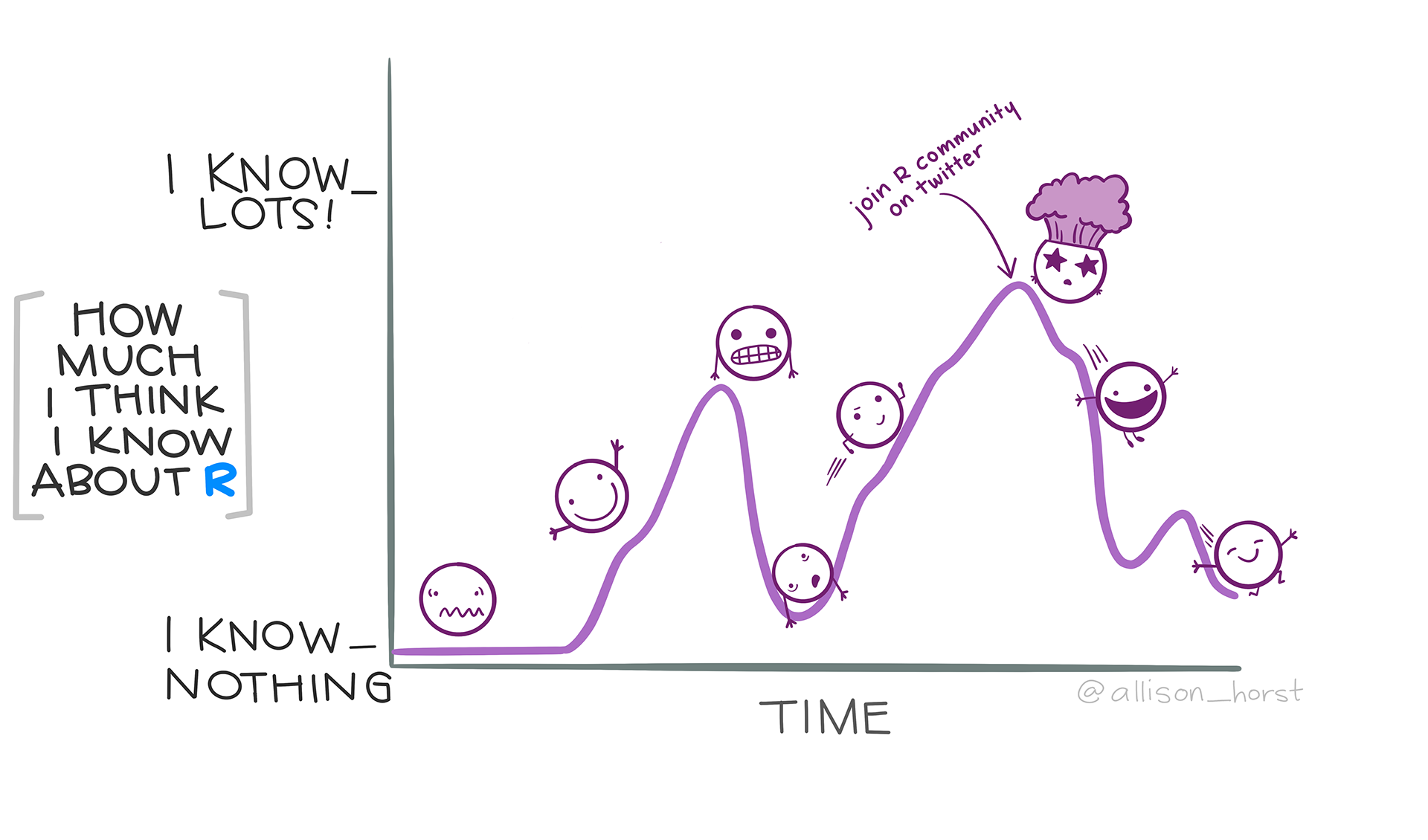
Where are you in your R learning timeline?